
[Very Important LLM System Design #10] Transformers : Inside the Architecture That Powers ChatGPT, BERT, and Modern AI: How They Actually Work - Part 10
All the technical details you need to know...
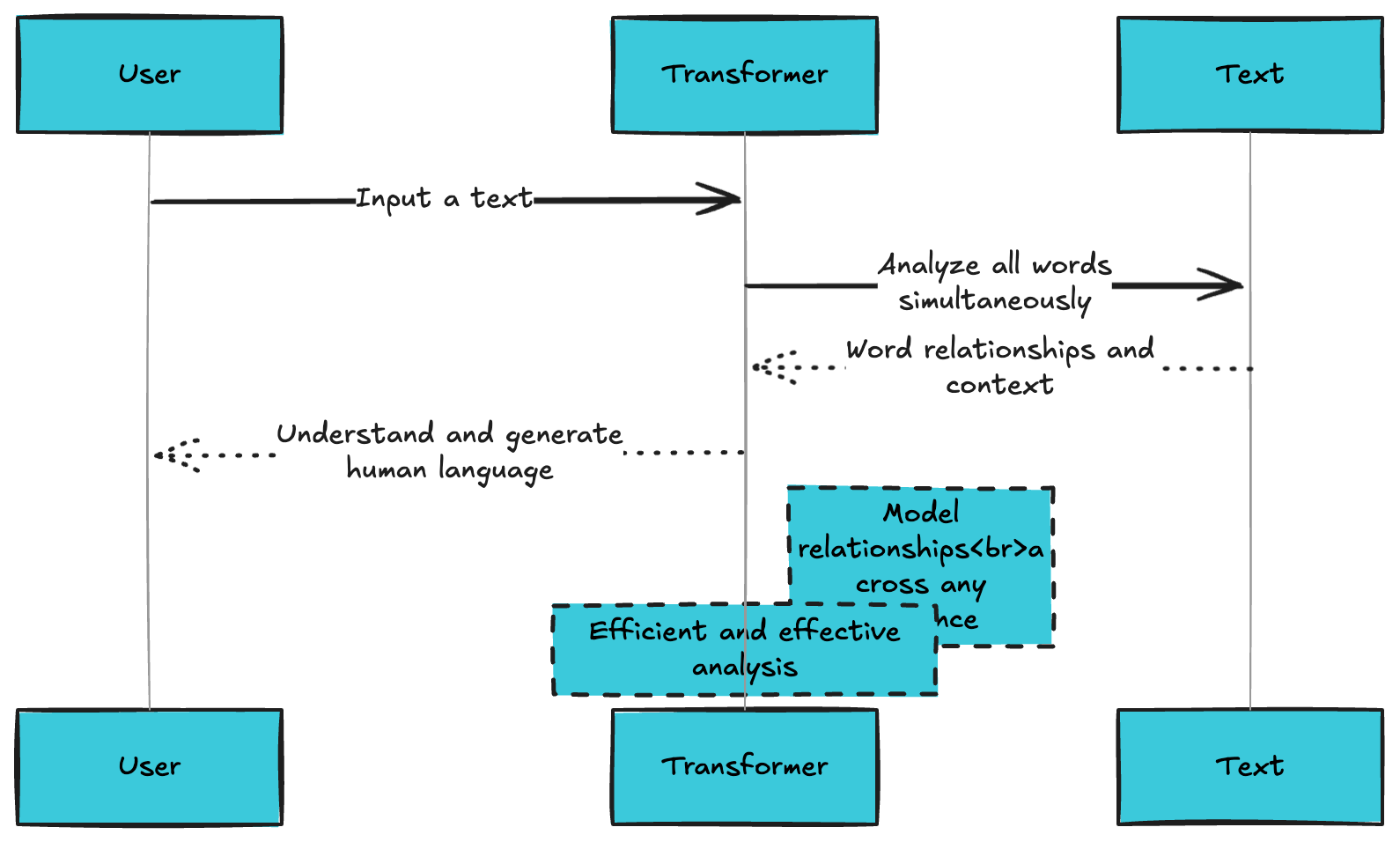
What Happens When You Type "Explain quantum physics"?
When you type a question into ChatGPT or any modern language model, a remarkable process unfolds in milliseconds. Your simple text query triggers one of the most sophisticated neural network architectures ever created - the Transformer. Let's trace exactly what happens from the moment you hit enter to when you see the first word of the response.
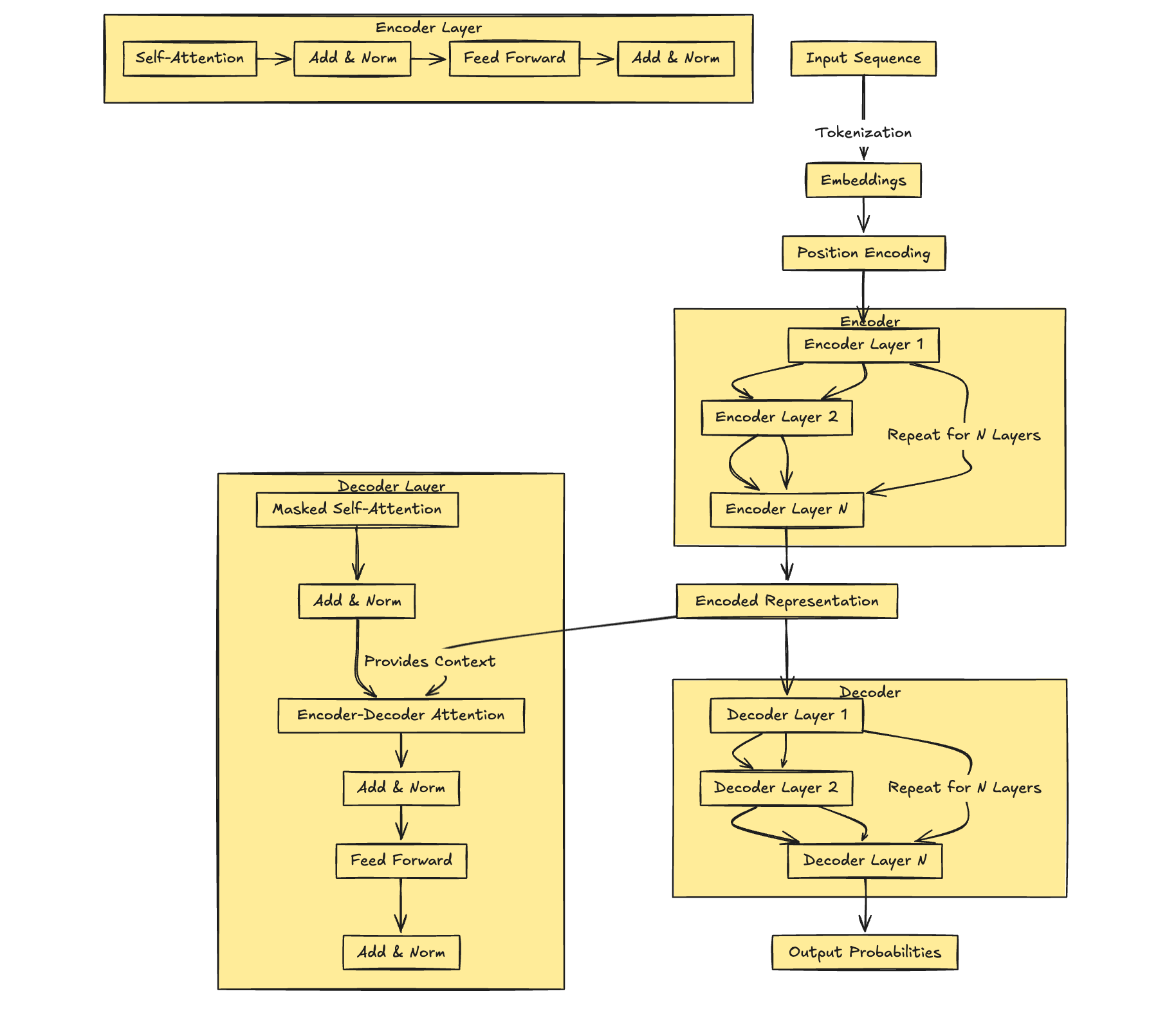
The Complete Query Processing Flow
┌─────────────────────────────────────────────────────────────┐
│ USER QUERY FLOW │
├─────────────────────────────────────────────────────────────┤
│ │
│ 1. INPUT PROCESSING │
│ ┌──────────────┐ │
│ │ User: "Explain quantum physics" │
│ │ Length: 3 tokens │
│ └──────────────┘ │
│ ↓ │
│ │
│ 2. TOKENIZATION (< 1ms) │
│ ┌──────────────────────────────────┐ │
│ │ Text → Token IDs │ │
│ │ "Explain" → 849 │ │
│ │ "quantum" → 31307 │ │
│ │ "physics" → 22027 │ │
│ │ Special tokens: [BOS] → 1 │ │
│ └──────────────────────────────────┘ │
│ ↓ │
│ │
│ 3. EMBEDDING LOOKUP (< 2ms) │
│ ┌──────────────────────────────────┐ │
│ │ Each token → 4096-dim vector │ │
│ │ "Explain": [0.23, -0.45, ...] │ │
│ │ "quantum": [0.67, 0.12, ...] │ │
│ │ "physics": [-0.34, 0.89, ...] │ │
│ │ + Positional encoding │ │
│ └──────────────────────────────────┘ │
│ ↓ │
│ │
│ 4. TRANSFORMER LAYERS (< 50ms) │
│ ┌──────────────────────────────────┐ │
│ │ 96 layers of processing: │ │
│ │ • Self-attention: context build │ │
│ │ • Feed-forward: knowledge recall │ │
│ │ • Layer norm: stabilization │ │
│ │ Each layer refines understanding │ │
│ └──────────────────────────────────┘ │
│ ↓ │
│ │
│ 5. GENERATION PROCESS (Variable) │
│ ┌──────────────────────────────────┐ │
│ │ Next token prediction: │ │
│ │ "Quantum" (95% confidence) │ │
│ │ Append to sequence → repeat │ │
│ │ Continue until [EOS] or limit │ │
│ └──────────────────────────────────┘ │
│ ↓ │
│ │
│ 6. OUTPUT FORMATTING │
│ ┌──────────────────────────────────┐ │
│ │ "Quantum physics is the branch │ │
│ │ of physics that studies the │ │
│ │ behavior of matter and energy │ │
│ │ at the atomic and subatomic..." │ │
│ └──────────────────────────────────┘ │
│ │
│ Total Latency: 53ms for first token ⚡ │
└─────────────────────────────────────────────────────────────┘
Performance Comparison: Before and After Transformers
Read previous parts -
Understanding Transformers & Large Language Models: How They Actually Work - Part 1
Understanding Transformers & Large Language Models: How They Actually Work - Part 2
[LLM System Design #3] Large Language Models: Pre-Training LLMs: How They Actually Work - Part 3
Below are the top 10 System Design Case studies for this week
Billions of Queries Daily : How Google Search Actually Works
100+ Million Requests per Second : How Amazon Shopping Cart Actually Works
Serving 132+ Million Users : Scaling for Global Transit Real Time Ride Sharing Market at Uber
3 Billion Daily Users : How Youtube Actually Scales
$100000 per BTC : How Bitcoin Actually Works
$320 Billion Crypto Transactions Volume: How Coinbase Actually Works
100K Events per Second : How Uber Real-Time Surge Pricing Actually Works
Processing 2 Billion Daily Queries : How Facebook Graph Search Actually Works
7 Trillion Messages Daily : Magic Behind LinkedIn Architecture and How It Actually Works
1 Billion Tweets Daily : Magic Behind Twitter Scaling and How It Actually Works
12 Million Daily Users: Inside Slack's Real-Time Messaging Magic and How it Actually Works
3 Billion Daily Users : How Youtube Actually Scales
1.5 Billion Swipes per Day : How Tinder Matching Actually Works
500+ Million Users Daily : How Instagram Stories Actually Work
2.9 Billion Daily Active Users : How Facebook News Feed Algorithm Actually Works
20 Billion Messages Daily: How Facebook Messenger Actually Works
8+ Billion Daily Views: How Facebook's Live Video Ranking Algorithm Works
How Discord's Real-Time Chat Scales to 200+ Million Users
80 Million Photos Daily : How Instagram Achieves Real Time Photo Sharing
Serving 1 Trillion Edges in Social Graph with 1ms Read Times : How Facebook TAO works
How Lyft Handles 2x Traffic Spikes during Peak Hours with Auto scaling Infrastructure..
┌─────────────────────────────────────────────────────────────┐
│ ARCHITECTURE PERFORMANCE COMPARISON │
├─────────────────────────────────────────────────────────────┤
│ │
│ Training Speed: │
│ RNN (LSTM): ████████████████████ 30 days │
│ Transformer: ██ 3 days │
│ 90% faster training │
│ │
│ Quality Metrics (BLEU Score): │
│ ┌────────────────────────────────────┐ │
│ │ ↑ │ │
│ │ 45 │ ┌─────── Transformer │
│ │ │ ┌──┘ │ │
│ │ 40 │ ┌───┘ +15 BLEU points │ │
│ │ │ ┌──┘ │ │
│ │ 35 │──┘ RNN/LSTM │ │
│ │ └────────────────────────→ │ │
│ │ Model Size (parameters) │ │
│ └────────────────────────────────────┘ │
│ │
│ Parallelization: │
│ ┌────────────────────────────────────┐ │
│ │ RNN: Sequential processing │ │
│ │ ━━━━━━━━━━━━━ (can't parallelize) │ │
│ │ │ │
│ │ Transformer: Parallel processing │ │
│ │ ━━━ ━━━ ━━━ ━━━ (full parallel) │ │
│ └────────────────────────────────────┘ │
│ │
│ Long Sequence Handling: │
│ • RNN: Forgets early context after 100+ tokens │
│ • Transformer: Perfect recall across 32K+ tokens │
│ • Result: 10x better long-form generation │
└─────────────────────────────────────────────────────────────┘