
[Launching LLM System Design ] Large Language Models: From Tokens to Optimization: How They Actually Work - Part 1
All the technical details you need to know...
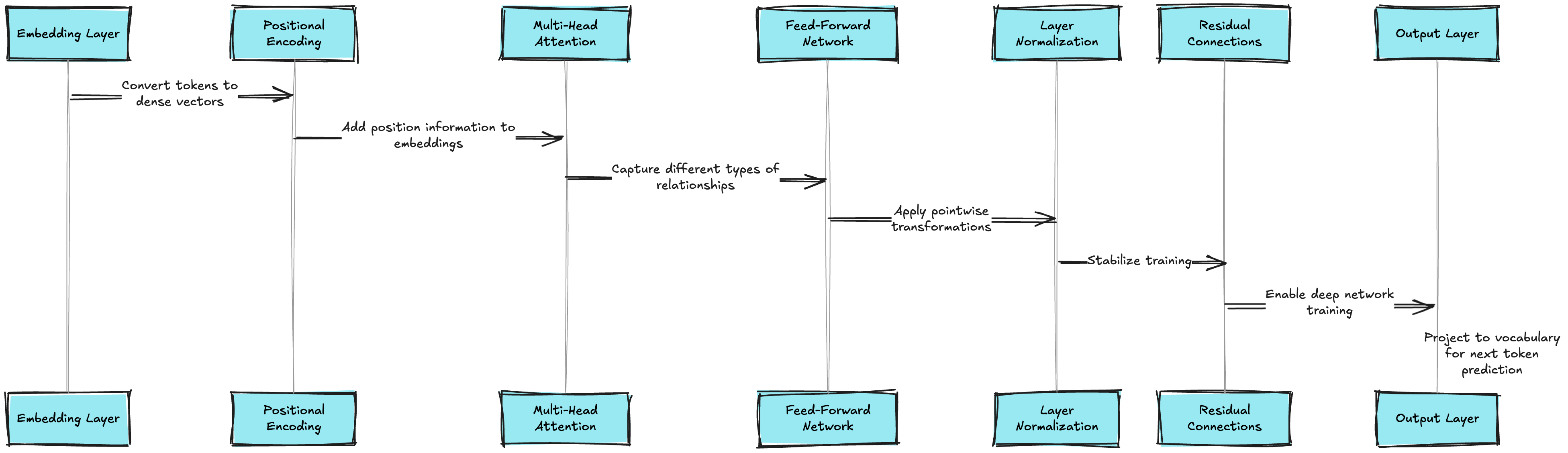
Table of Contents
Tokens
Embeddings
Transformers
Variants
Optimization
LLMs
1. Tokens
What are Tokens?
Tokens are the fundamental units that language models use to process text. Think of tokens as the "words" that a computer understands - they can be actual words, parts of words (subwords), or even individual characters, depending on the tokenization strategy used.
Diagram 1: Text-to-Token Conversion Process
Input Text: "Hello world! How are you?"
Step 1: Raw Text Processing
"Hello world! How are you?" → ["Hello", " world", "!", " How", " are", " you", "?"]
Step 2: Token ID Mapping
["Hello", " world", "!", " How", " are", " you", "?"] → [15496, 995, 0, 1374, 389, 345, 30]
Step 3: Model Input
[15496, 995, 0, 1374, 389, 345, 30] → Neural Network Processing
Diagram 2: Different Tokenization Strategies
Word-level Tokenization:
"running" → ["running"] (1 token)
Subword Tokenization (BPE):
"running" → ["run", "ning"] (2 tokens)
Character-level Tokenization:
"running" → ["r", "u", "n", "n", "i", "n", "g"] (7 tokens)
Byte-level Tokenization:
"running" → [114, 117, 110, 110, 105, 110, 103] (7 byte tokens)
Diagram 3: BPE (Byte Pair Encoding) Algorithm Working
Step 1: Initialize with characters
Vocabulary: {h, e, l, o, w, r, d}
Text: "hello world" → [h, e, l, l, o, w, o, r, l, d]
Step 2: Count adjacent pairs
Pairs: {he: 1, el: 2, ll: 1, lo: 2, ow: 1, wo: 1, or: 1, rl: 1, ld: 1}
Most frequent: "el" and "lo" (count: 2)
Step 3: Merge most frequent pair "el" → "el"
New vocab: {h, el, l, o, w, r, d}
Text: "hello world" → [h, el, l, o, w, o, r, l, d]
Step 4: Repeat until desired vocab size
Final result: [hel, lo, wor, ld] (4 tokens)
Efficient balance between vocabulary size and sequence length
Diagram 4: Token Vocabulary and OOV Handling
Standard Vocabulary (50K tokens):
┌─────────────────────────────────┐
│ Common words: "the", "and", "is"│
│ Subwords: "ing", "tion", "pre" │
│ Rare words: "antidisestablish" │
│ Special: [PAD], [UNK], [MASK] │
└─────────────────────────────────┘
Out-of-Vocabulary (OOV) Word: "supercalifragilisticexpialidocious"
↓
Subword Decomposition Process:
"super" → Found in vocab ✓
"cal" → Found in vocab ✓
"ifrag" → Not found, break down further
"i" → Found ✓, "frag" → Found ✓
...continuing...
Final tokens: ["super", "cal", "i", "frag", "il", "istic", "exp", "ial", "id", "oci", "ous"]
Never produces [UNK] token - always decomposable!
Why Tokens are Used and Where
Why Tokens are Essential:
Computational Efficiency: Neural networks work with numbers, not raw text
Vocabulary Management: Handle millions of possible words with a fixed vocabulary size
Cross-lingual Support: Subword tokens can handle multiple languages efficiently
Out-of-vocabulary Handling: Break unknown words into known subword pieces
Below are the top 10 System Design Case studies for this week
Billions of Queries Daily : How Google Search Actually Works
100+ Million Requests per Second : How Amazon Shopping Cart Actually Works
Serving 132+ Million Users : Scaling for Global Transit Real Time Ride Sharing Market at Uber
3 Billion Daily Users : How Youtube Actually Scales
$100000 per BTC : How Bitcoin Actually Works
$320 Billion Crypto Transactions Volume: How Coinbase Actually Works
100K Events per Second : How Uber Real-Time Surge Pricing Actually Works
Processing 2 Billion Daily Queries : How Facebook Graph Search Actually Works
7 Trillion Messages Daily : Magic Behind LinkedIn Architecture and How It Actually Works
1 Billion Tweets Daily : Magic Behind Twitter Scaling and How It Actually Works
12 Million Daily Users: Inside Slack's Real-Time Messaging Magic and How it Actually Works
3 Billion Daily Users : How Youtube Actually Scales
1.5 Billion Swipes per Day : How Tinder Matching Actually Works
500+ Million Users Daily : How Instagram Stories Actually Work
2.9 Billion Daily Active Users : How Facebook News Feed Algorithm Actually Works
20 Billion Messages Daily: How Facebook Messenger Actually Works
8+ Billion Daily Views: How Facebook's Live Video Ranking Algorithm Works
How Discord's Real-Time Chat Scales to 200+ Million Users
80 Million Photos Daily : How Instagram Achieves Real Time Photo Sharing
Serving 1 Trillion Edges in Social Graph with 1ms Read Times : How Facebook TAO works
How Lyft Handles 2x Traffic Spikes during Peak Hours with Auto scaling Infrastructure..
Where Tokens are Used:
Input Processing: Converting user queries into model-readable format
Training Data: All training text is tokenized before feeding to the model
Inference: Every prediction starts with tokenization
Multilingual Models: Handling diverse languages with shared token vocabularies
How to Use Tokens
Practical Implementation:
# Using Hugging Face Transformers
from transformers import AutoTokenizer
# Load a tokenizer
tokenizer = AutoTokenizer.from_pretrained("gpt2")
# Tokenize text
text = "Hello world! How are you?"
tokens = tokenizer.encode(text)
print(f"Tokens: {tokens}")
# Decode back to text
decoded = tokenizer.decode(tokens)
print(f"Decoded: {decoded}")
# Get token-to-text mapping
token_text_pairs = [(token, tokenizer.decode([token]))
for token in tokens]
print(f"Token mappings: {token_text_pairs}")
Best Practices:
Choose appropriate tokenization strategy based on your use case
Consider vocabulary size vs. sequence length trade-offs
Handle special tokens (padding, start/end markers) properly
Be aware of tokenization differences between models
2. Embeddings
What are Embeddings?
Embeddings are dense vector representations that capture semantic meaning of tokens in a continuous mathematical space. They transform discrete tokens into continuous vectors that neural networks can effectively process and learn from.
Diagram 1: Token to Embedding Transformation
Token ID: 15496 ("Hello")
↓
Embedding Matrix (Vocab Size × Embedding Dim)
[15496] → Row 15496: [0.2, -0.1, 0.8, 0.3, -0.5, ..., 0.4]
↓
Dense Vector (512-dimensional)
Embedding: [0.2, -0.1, 0.8, 0.3, -0.5, 0.7, -0.2, ..., 0.4]
Diagram 2: Semantic Space Representation
2D Visualization (actual embeddings are 512+ dimensional):
cat • • kitten
\ /
pet
|
dog • | • puppy
\|/
animal
car • • vehicle
\ /
automobile
|
truck •|• bus
\|/
transport
Similar concepts cluster together in embedding space
Distance represents semantic similarity