
Understanding Transformers & Large Language Models: How They Actually Work - Part 2
All the technical details you need to know...
You can read part 1 here :
Understanding Transformers & Large Language Models: How They Actually Work - Part 1

The field of artificial intelligence has been revolutionized by Transformers and Large Language Models (LLMs). This comprehensive guide takes you through these complex technologies step by step, with detailed visual explanations and practical applications.
Part 2
Cost Optimization Strategies
In the world of Large Language Models, computational costs can quickly spiral out of control. Understanding how to optimize these costs while maintaining quality is crucial for practical deployment.
┌─────────────────────────────────────────────────────────────┐
│ Cost Optimization Cascade │
│ │
│ User Query │
│ │ │
│ ▼ │
│ ┌─────────────┐ │
│ │ Complexity │ │
│ │ Analyzer │ │
│ └──────┬──────┘ │
│ │ │
│ ┌────┴────┬────────┬──────────┐ │
│ ▼ ▼ ▼ ▼ │
│ Simple Moderate Complex Research │
│ │ │ │ │ │
│ ▼ ▼ ▼ ▼ │
│ Small Medium Large Multiple │
│ Model Model Model Models │
│ ($0.0001) ($0.001) ($0.01) ($0.05+) │
│ │
│ Example Routing: │
│ • "What's 2+2?" → Small model │
│ • "Explain quantum physics" → Medium model │
│ • "Write a business plan" → Large model │
│ • "Research and analyze..." → Multi-model pipeline │
└─────────────────────────────────────────────────────────────┘
The cost optimization cascade represents a sophisticated approach to managing inference costs. Here's how it works:
Complexity Analysis: The first step involves analyzing the input query to determine its complexity. This can be done through:
Keyword detection (mathematical terms, technical jargon, etc.)
Query length and structure analysis
Historical pattern matching
Lightweight classification models
Model Selection Strategy:
Small Models (1-3B parameters): Handle simple factual queries, basic math, and straightforward questions. These cost roughly $0.0001 per 1K tokens.
Medium Models (7-13B parameters): Process moderate complexity tasks requiring reasoning, detailed explanations, or domain knowledge. Cost approximately $0.001 per 1K tokens.
Large Models (70B+ parameters): Reserved for complex creative tasks, sophisticated reasoning, and nuanced understanding. These can cost $0.01 or more per 1K tokens.
Multi-Model Pipelines: For research tasks, combine multiple models with different specializations, potentially costing $0.05+ per query.
Below are the top 10 System Design Case studies for this week
Billions of Queries Daily : How Google Search Actually Works
100+ Million Requests per Second : How Amazon Shopping Cart Actually Works
Serving 132+ Million Users : Scaling for Global Transit Real Time Ride Sharing Market at Uber
3 Billion Daily Users : How Youtube Actually Scales
$100000 per BTC : How Bitcoin Actually Works
$320 Billion Crypto Transactions Volume: How Coinbase Actually Works
100K Events per Second : How Uber Real-Time Surge Pricing Actually Works
Processing 2 Billion Daily Queries : How Facebook Graph Search Actually Works
7 Trillion Messages Daily : Magic Behind LinkedIn Architecture and How It Actually Works
1 Billion Tweets Daily : Magic Behind Twitter Scaling and How It Actually Works
12 Million Daily Users: Inside Slack's Real-Time Messaging Magic and How it Actually Works
3 Billion Daily Users : How Youtube Actually Scales
1.5 Billion Swipes per Day : How Tinder Matching Actually Works
500+ Million Users Daily : How Instagram Stories Actually Work
2.9 Billion Daily Active Users : How Facebook News Feed Algorithm Actually Works
20 Billion Messages Daily: How Facebook Messenger Actually Works
8+ Billion Daily Views: How Facebook's Live Video Ranking Algorithm Works
How Discord's Real-Time Chat Scales to 200+ Million Users
80 Million Photos Daily : How Instagram Achieves Real Time Photo Sharing
Serving 1 Trillion Edges in Social Graph with 1ms Read Times : How Facebook TAO works
How Lyft Handles 2x Traffic Spikes during Peak Hours with Auto scaling Infrastructure..
Implementation Best Practices:
Caching Layer: Implement semantic caching to avoid reprocessing similar queries
Batch Processing: Group similar complexity queries for efficient GPU utilization
Fallback Mechanisms: If a smaller model fails, automatically escalate to larger models
Quality Monitoring: Track success rates to optimize routing thresholds
Part 5: Deep Dive into Transformer Components
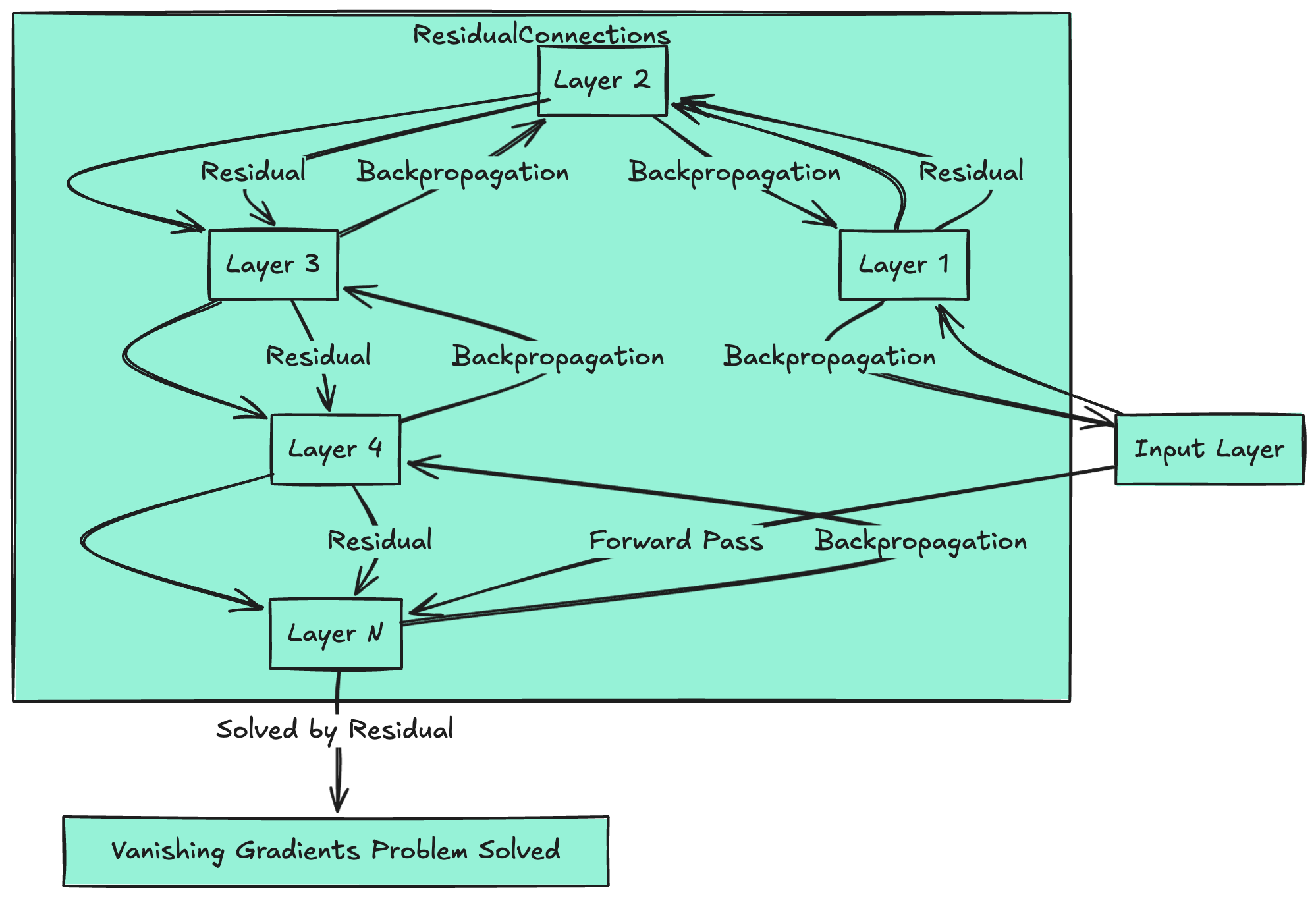
Residual Connections and Layer Normalization
Residual connections and layer normalization are crucial for training deep networks:
┌─────────────────────────────────────────────────────────────┐
│ Residual Connection & Layer Normalization │
│ │
│ Why Residual Connections? │
│ │
│ Without Residuals: With Residuals: │
│ X → Layer → Y X → Layer → Y │
│ │ │ │
│ Gradient flow: └────+───┘ │
│ ∂L/∂X = ∂L/∂Y · ∂Y/∂X ∂L/∂X = ∂L/∂Y·(1 + ∂Y/∂X)│
│ ↓ ↓ │
│ Can vanish/explode Always has direct path │
│ │
│ Layer Normalization: │
│ ┌─────────────────────────────────────────┐ │
│ │ Input: x = [0.5, 2.0, -1.0, 3.0] │ │
│ │ │ │
│ │ Mean μ = 1.125 │ │
│ │ Std σ = 1.478 │ │
│ │ │ │
│ │ Normalized: x̂ = (x - μ)/σ │ │
│ │ Result: [-0.42, 0.59, -1.49, 1.31] │ │
│ │ │ │
│ │ Scale & Shift: y = γ·x̂ + β │ │
│ └─────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘
Residual Connections: The Highway for Gradients