


Understanding Transformers & Large Language Models: How They Actually Work - Part 1
All the technical details you need to know...
The field of artificial intelligence has been revolutionized by Transformers and Large Language Models (LLMs). This comprehensive guide takes you through these complex technologies step by step, with detailed visual explanations and practical applications.
Part 1: The Foundation - Tokens and Embeddings
What Are Tokens? The Building Blocks of Language AI
At the heart of any language model lies the concept of tokens - the fundamental building blocks of text processing. To understand tokens, imagine trying to teach a computer to read. Just as children learn to read by recognizing letters, then words, computers need to break down text into manageable pieces.
The Tokenization Process: From Human Text to Machine Understanding
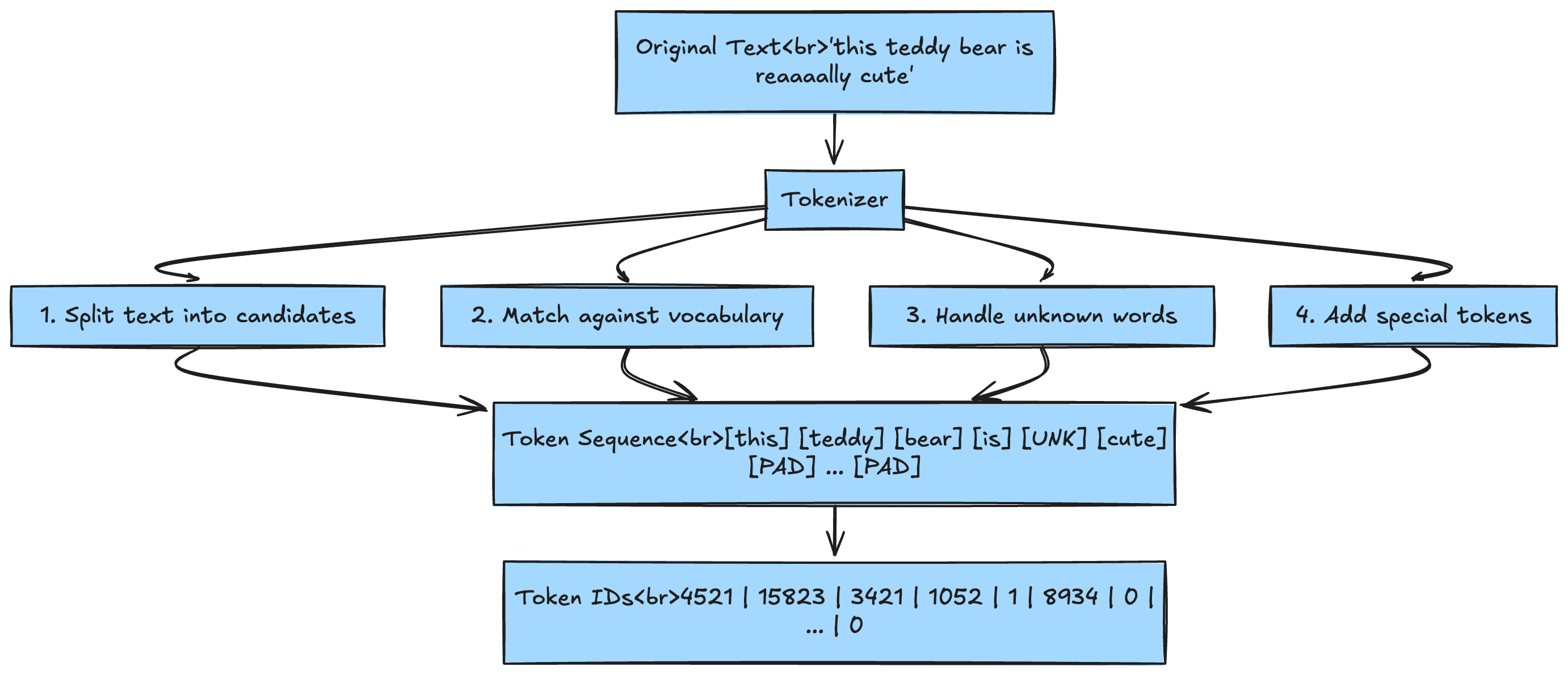
Let's examine the tokenization process in detail:
┌─────────────────────────────────────────────────────────────┐
│ Original Text │
│ "this teddy bear is reaaaally cute" │
└─────────────────────────────┬───────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ Tokenizer │
│ 1. Split text into candidates │
│ 2. Match against vocabulary │
│ 3. Handle unknown words │
│ 4. Add special tokens │
└─────────────────────────────┬───────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ Token Sequence │
│ [this] [teddy] [bear] [is] [UNK] [cute] [PAD] ... [PAD] │
│ ↓ ↓ ↓ ↓ ↓ ↓ ↓ │
│ 4521 15823 3421 1052 1 8934 0 ... 0 │
│ (Token IDs) │
└─────────────────────────────────────────────────────────────┘
Several important things happen during tokenization:
Vocabulary Matching: Each word is checked against the model's vocabulary
Unknown Token Handling: "reaaaally" isn't in the vocabulary, so it becomes
[UNK](unknown token)Padding:
[PAD]tokens fill empty positions to ensure all sequences have the same lengthSpecial Tokens: Models use special tokens like
[CLS](classification),[SEP](separator), and[BOS]/[EOS](beginning/end of sequence)
Why Tokenization Matters: The Hidden Complexity
The choice of tokenization strategy profoundly impacts every aspect of model performance:
┌─────────────────────────────────────────────────────────────┐
│ Tokenization Impact │
├─────────────────────────┬───────────────────────────────────┤
│ Memory Efficiency │ Smaller vocab = Less memory │
│ │ But longer sequences needed │
├─────────────────────────┼───────────────────────────────────┤
│ Generalization │ Subwords help with new words │
│ │ "unhappy" → ["un", "happy"] │
├─────────────────────────┼───────────────────────────────────┤
│ Context Windows │ Token count determines │
│ │ how much text fits in context │
├─────────────────────────┼───────────────────────────────────┤
│ Computational Cost │ More tokens = More computation │
│ │ O(n²) attention complexity │
└─────────────────────────┴───────────────────────────────────┘
Types of Tokenizers: A Detailed Comparison
1. Word-Level Tokenization: The Intuitive Approach
Word-level tokenization is the most straightforward approach - each word becomes a token.
┌─────────────────────────────────────────────────────────────┐
│ Word-Level Tokenization │
│ │
│ Input: "The quick brown fox jumps" │
│ │
│ Step 1: Split by whitespace │
│ ↓ │
│ ["The", "quick", "brown", "fox", "jumps"] │
│ │
│ Step 2: Map to vocabulary IDs │
│ ↓ │
│ [523, 1847, 3921, 7823, 9213] │
│ │
│ Vocabulary Size Required: ~170,000 words (English) │
└─────────────────────────────────────────────────────────────┘
Advantages:
✅ Easy to interpret, short sequences
✅ Clear boundaries, word meanings preserved
Disadvantages:
❌ Massive vocabulary (170,000+ words)
❌ No morphological understanding
❌ Poor generalization for new words
❌ Language-specific limitations
2. Subword-Level Tokenization: The Sweet Spot
Subword tokenization breaks words into meaningful parts, balancing vocabulary size with sequence length.
Byte-Pair Encoding (BPE) Algorithm Visualization:
┌─────────────────────────────────────────────────────────────┐
│ BPE Training Process │
│ │
│ Initial: Characters as tokens │
│ Text: "low lower lowest" │
│ │
│ Step 1: Count character pairs │
│ 'l','o' → 3 times │
│ 'o','w' → 3 times │
│ │
│ Step 2: Merge most frequent pair │
│ 'lo' becomes new token │
│ │
│ Step 3: Continue until vocabulary size reached │
│ Final tokens: ['l', 'o', 'w', 'lo', 'low', 'er', 'est'] │
└─────────────────────────────────────────────────────────────┘