


[Most Important LLM System Design #8] Understanding LLMs: Why RAG is the Game-Changer : How They Actually Work - Part 8
All the technical details you need to know...
Introduction
Picture this: You're using ChatGPT to get information about a recent breakthrough in quantum computing, but the model responds with outdated information or, worse, makes up facts that sound convincing but are completely wrong. This is the fundamental problem that Retrieval-Augmented Generation (RAG) was designed to solve.
RAG represents one of the most significant advances in AI since the transformer architecture itself. It's not just another incremental improvement – it's a paradigm shift that addresses the core limitations of Large Language Models (LLMs): hallucinations, outdated knowledge, and inability to access real-time information.
Chapter 1: Understanding RAG - The Foundation
What is RAG?
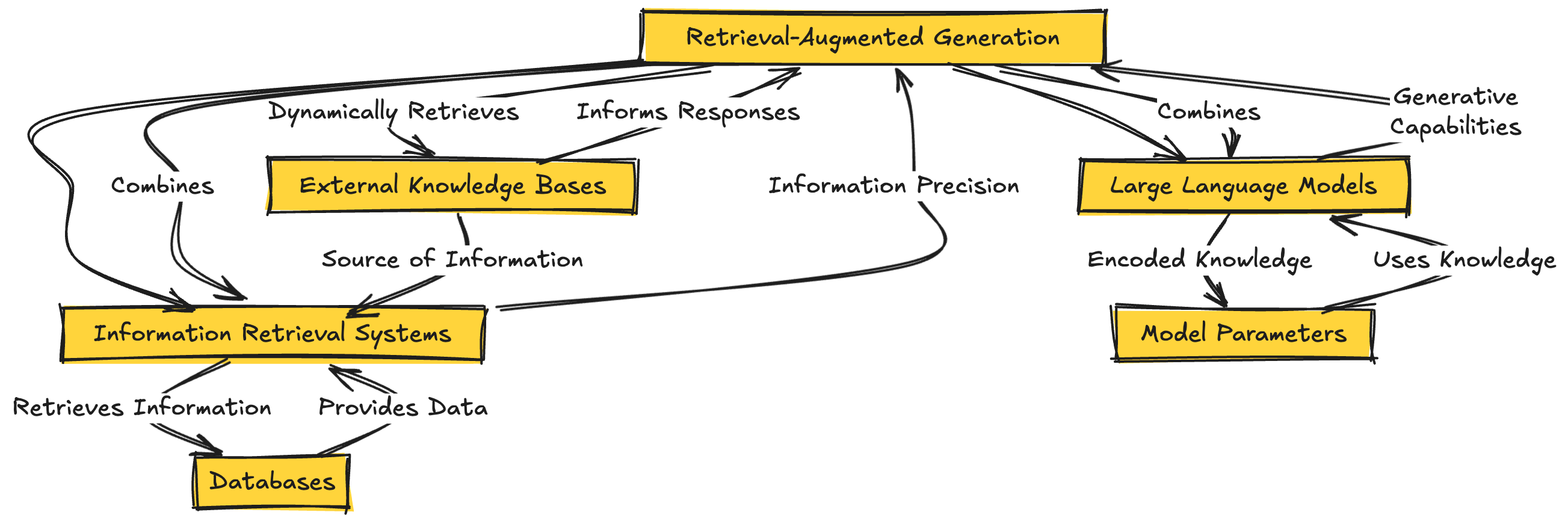
Retrieval-Augmented Generation is a hybrid approach that combines the generative capabilities of Large Language Models with the precision of information retrieval systems. Instead of relying solely on the knowledge encoded in model parameters during training, RAG dynamically retrieves relevant information from external knowledge bases to inform its responses.
Think of RAG as giving an AI assistant access to a vast, constantly updated library. When you ask a question, the AI doesn't just rely on what it "remembers" from training – it actively searches through the library to find the most relevant, up-to-date information to answer your query.
Read LLMs System Design (recommended to complete previous parts) -
Understanding Transformers & Large Language Models: How They Actually Work - Part 1
Understanding Transformers & Large Language Models: How They Actually Work - Part 2
[LLM System Design #3] Large Language Models: Pre-Training LLMs: How They Actually Work - Part 3
Why RAG Matters: The Critical Problems It Solves
1. The Hallucination Problem LLMs are notorious for generating plausible-sounding but factually incorrect information. RAG grounds responses in actual retrieved documents, dramatically reducing hallucinations.
2. Knowledge Cutoff Limitations Traditional LLMs are frozen in time at their training cutoff. RAG allows models to access current information, making them perpetually up-to-date.
3. Domain-Specific Knowledge Gaps Pre-trained models may lack depth in specialized domains. RAG can incorporate industry-specific knowledge bases, legal documents, medical literature, or proprietary company data.
4. Transparency and Verifiability RAG provides source citations, making AI responses auditable and trustworthy – crucial for enterprise and critical applications.
How RAG Works: The Three-Step Process
[User Query] → [Retrieve Relevant Docs] → [Generate Augmented Response]
↓ ↓ ↓
"What are the Top-K most similar Response citing and
latest trends documents from incorporating retrieved
in quantum knowledge base information
computing?"
Chapter 2: Traditional RAG Pipeline - The Four Pillars of Information Retrieval
Before diving into the evolution of RAG systems, it's crucial to understand the traditional RAG pipeline that forms the foundation of all retrieval-augmented generation systems. This pipeline consists of four essential steps that work together to transform raw data into intelligent, contextual responses.
The Traditional RAG Architecture
[Raw Data Sources] → [Data Indexing] → [Vector Database]
↑
[User Query] → [Query Processing] → [Search & Ranking] ──┘
↓
[Retrieved Documents] ← ┘
↓
[Prompt Augmentation]
↓
[Enhanced Prompt]
↓
[LLM Generation]
↓
[Final Response]
Key Steps:
1. Data Indexing: Organize & vectorize knowledge
2. Query Processing: Optimize user queries
3. Search & Ranking: Find relevant documents
4. Prompt Augmentation: Combine query + context
Step 1: Data Indexing - Organizing Knowledge for Lightning-Fast Retrieval
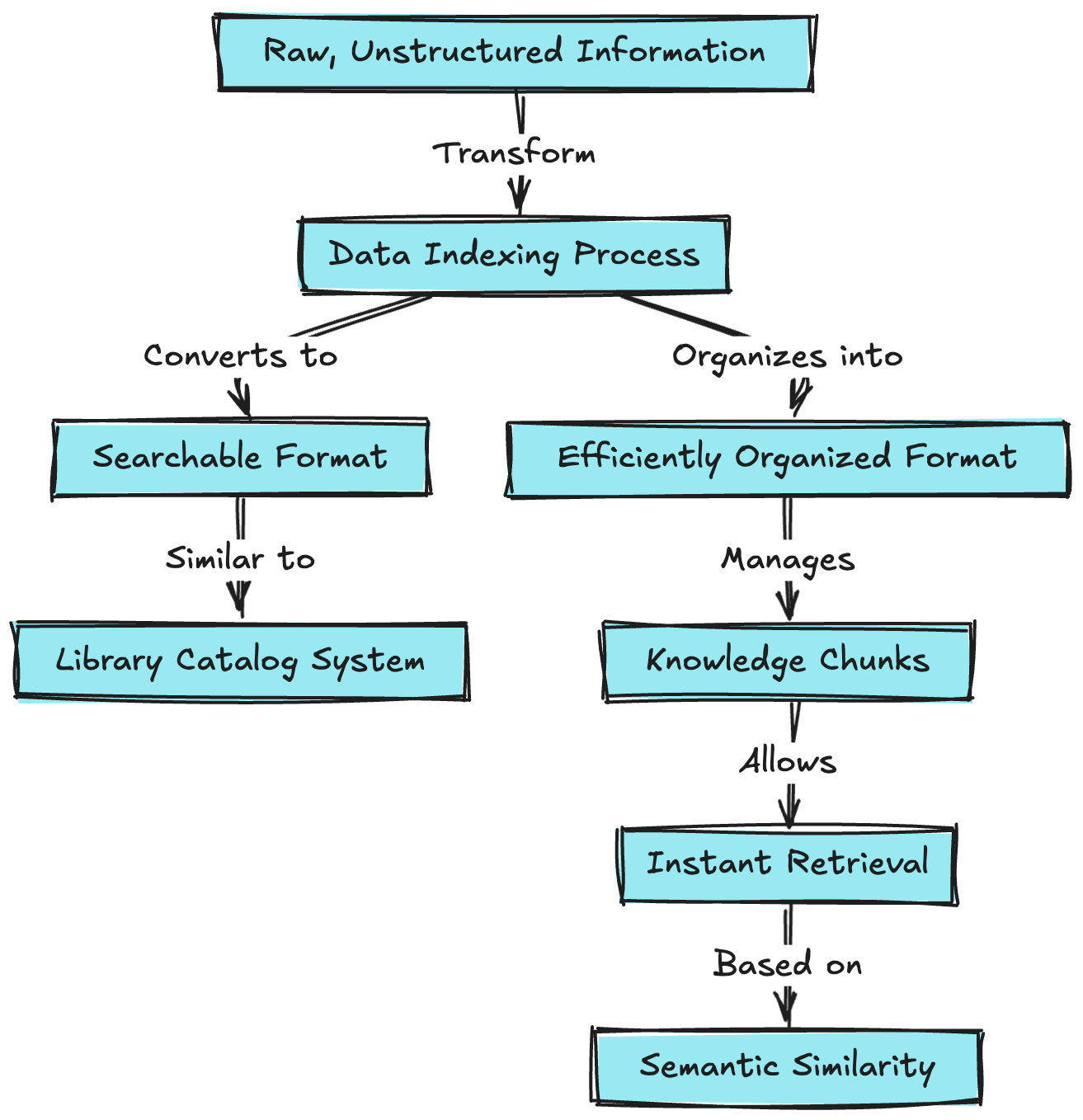
What is Data Indexing?
Data indexing is the process of transforming raw, unstructured information into a searchable, efficiently organized format. Think of it as creating a sophisticated library catalog system, but instead of books, we're cataloging knowledge chunks that can be instantly retrieved based on semantic similarity.
Why Data Indexing Matters:
Speed: Enables sub-second retrieval from millions of documents
Accuracy: Proper indexing ensures relevant information is found
Scalability: Handles growing knowledge bases without performance degradation
Flexibility: Supports various search strategies and ranking algorithms
The Three-Phase Indexing Process:
[Raw Documents] → [Document Processing] → [Intelligent Chunking] → [Vector Embedding] → [Index Storage]
↓ ↓ ↓
• Text Extraction • Semantic Boundaries • Embedding Models
• Cleaning & Normal. • Size Optimization • Vector Generation
• Metadata Extract. • Overlap Strategies • Dimensionality
Below are the top 10 System Design Case studies for this week
Billions of Queries Daily : How Google Search Actually Works
100+ Million Requests per Second : How Amazon Shopping Cart Actually Works
Serving 132+ Million Users : Scaling for Global Transit Real Time Ride Sharing Market at Uber
3 Billion Daily Users : How Youtube Actually Scales
$100000 per BTC : How Bitcoin Actually Works
$320 Billion Crypto Transactions Volume: How Coinbase Actually Works
100K Events per Second : How Uber Real-Time Surge Pricing Actually Works
Processing 2 Billion Daily Queries : How Facebook Graph Search Actually Works
7 Trillion Messages Daily : Magic Behind LinkedIn Architecture and How It Actually Works
1 Billion Tweets Daily : Magic Behind Twitter Scaling and How It Actually Works
12 Million Daily Users: Inside Slack's Real-Time Messaging Magic and How it Actually Works
3 Billion Daily Users : How Youtube Actually Scales
1.5 Billion Swipes per Day : How Tinder Matching Actually Works
500+ Million Users Daily : How Instagram Stories Actually Work
2.9 Billion Daily Active Users : How Facebook News Feed Algorithm Actually Works
20 Billion Messages Daily: How Facebook Messenger Actually Works
8+ Billion Daily Views: How Facebook's Live Video Ranking Algorithm Works
How Discord's Real-Time Chat Scales to 200+ Million Users
80 Million Photos Daily : How Instagram Achieves Real Time Photo Sharing
Serving 1 Trillion Edges in Social Graph with 1ms Read Times : How Facebook TAO works
How Lyft Handles 2x Traffic Spikes during Peak Hours with Auto scaling Infrastructure..
Document Processing Strategies:
Text Extraction and Cleaning:
[Raw Document] → [Format Detection] → [Text Extraction] → [Cleaning] → [Normalization] → [Processed Text]
↓ ↓ ↓ ↓ ↓
PDF/HTML/DOC Check file type Extract content Remove noise Standard format
Various formats Route to parser Handle encoding Fix artifacts Clean whitespace
def process_document(raw_doc):
# Extract text from various formats
if raw_doc.type == 'pdf':
text = extract_pdf_text(raw_doc)
elif raw_doc.type == 'html':
text = extract_html_content(raw_doc)
# Clean and normalize
cleaned_text = remove_artifacts(text)
normalized_text = normalize_whitespace(cleaned_text)
# Extract metadata
metadata = {
'source': raw_doc.source,
'created_date': raw_doc.timestamp,
'document_type': raw_doc.type,
'language': detect_language(normalized_text)
}
return normalized_text, metadata
Intelligent Chunking Strategies:
Fixed-Size Chunking:
[Long Document] → [Split by Words] → [Create Chunks] → [Add Overlap] → [Indexed Chunks]
↓ ↓ ↓ ↓ ↓
"The AI system Split into [Chunk 1: 512] Add 50 word Store with
revolution..." word array [Chunk 2: 512] overlap metadata
[Chunk 3: 512] for context
def fixed_size_chunking(text, chunk_size=512, overlap=50):
words = text.split()
chunks = []
for i in range(0, len(words), chunk_size - overlap):
chunk = ' '.join(words[i:i + chunk_size])
chunks.append({
'content': chunk,
'start_idx': i,
'end_idx': min(i + chunk_size, len(words))
})
return chunks
Semantic Chunking: