
[Most Important LLM System Design #6] Understanding Tokenization - The Bridge Between Human Language and Machine Understanding : How They Actually Work - Part 7
All the technical details you need to know...
If you've ever wondered why ChatGPT sometimes struggles with simple word counting, why it occasionally "forgets" parts of words, or why certain languages seem to work better than others—the answer lies in a seemingly mundane but absolutely critical process called tokenization.
Tokenization is the unsung hero of language model success. While developers obsess over model architectures, training strategies, and fine-tuning techniques, they often overlook the fundamental process that converts human language into the numerical representations that models can actually understand. This oversight is costly—poor tokenization can cripple even the most sophisticated language models, while excellent tokenization can make smaller models punch above their weight.
Tokenization isn't just a preprocessing step—it's the foundation that determines your model's vocabulary efficiency, computational cost, generalization ability, and ultimate performance across languages and domains.
Part 1: Understanding Tokenization - The Bridge Between Human Language and Machine Understanding
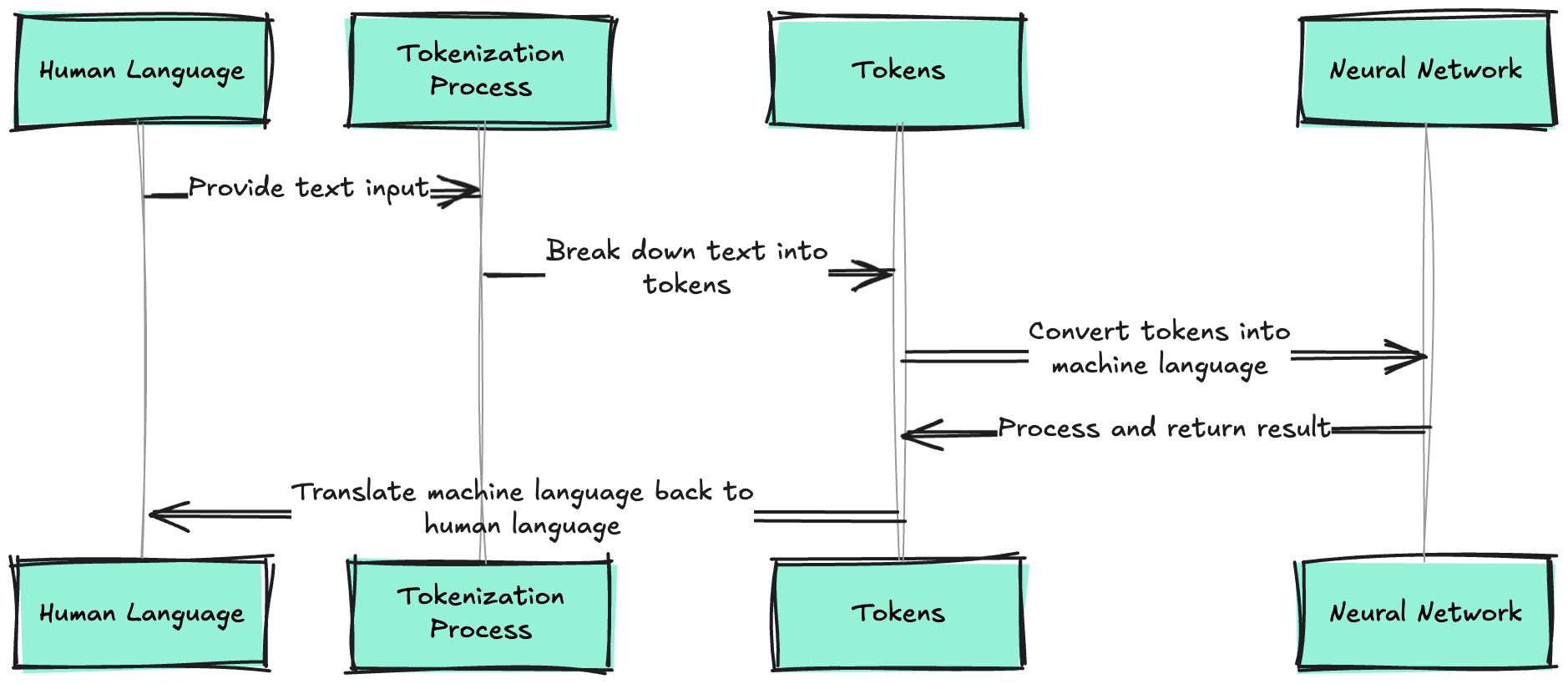
What Is Tokenization?
Tokenization is the process of breaking down text into smaller, manageable units called tokens that language models can process. Think of it as translating human language into a "machine language" that neural networks can understand and manipulate mathematically.
But tokenization is far more sophisticated than simple word splitting. Modern tokenization algorithms must balance multiple competing objectives: preserving semantic meaning, maintaining computational efficiency, handling rare words gracefully, and ensuring consistent behavior across different languages and domains.
Read previous parts -
Understanding Transformers & Large Language Models: How They Actually Work - Part 1
Understanding Transformers & Large Language Models: How They Actually Work - Part 2
[LLM System Design #3] Large Language Models: Pre-Training LLMs: How They Actually Work - Part 3
The fundamental challenge is this: humans communicate using a virtually infinite vocabulary of words, phrases, and expressions, but machines need to work with a finite, fixed vocabulary. Tokenization is the bridge that makes this possible.
Diagram 1: The Tokenization Process Overview
HUMAN TEXT TO MACHINE TOKENS: THE COMPLETE PIPELINE
RAW INPUT TEXT:
┌─────────────────────────────────────────────────────────┐
│ "The AI revolution is transforming industries worldwide" │
└─────────────────────────────────────────────────────────┘
↓
TEXT PREPROCESSING:
┌─────────────────────────────────────────────────────────┐
│ • Normalization (Unicode, case handling) │
│ • Special character handling │
│ • Whitespace standardization │
│ │
│ Result: Clean, standardized text │
└─────────────────────────────────────────────────────────┘
↓
TOKENIZATION ALGORITHM:
┌─────────────────────────────────────────────────────────┐
│ SUBWORD SPLITTING │
│ │
│ BPE/WordPiece/SentencePiece Algorithm: │
│ "transforming" → ["transform", "ing"] │
│ "industries" → ["industr", "ies"] │
│ "worldwide" → ["world", "wide"] │
│ │
│ Vocabulary Lookup: │
│ "The" → Token ID: 2421 │
│ "AI" → Token ID: 15698 │
│ "revolution" → Token ID: 9881 │
│ "is" → Token ID: 2003 │
│ ... │
└─────────────────────────────────────────────────────────┘
↓
TOKEN SEQUENCE OUTPUT:
┌─────────────────────────────────────────────────────────┐
│ Token IDs: [2421, 15698, 9881, 2003, 4758, 2003, ...] │
│ Token Text: ["The", "AI", "revolution", "is", ...] │
│ │
│ Properties: │
│ • Fixed vocabulary size (e.g., 50,000 tokens) │
│ • Each token maps to unique integer ID │
│ • Reversible process (can reconstruct original) │
│ • Ready for embedding lookup │
└─────────────────────────────────────────────────────────┘
↓
EMBEDDING LOOKUP:
┌─────────────────────────────────────────────────────────┐
│ Token ID → Dense Vector Representation │
│ │
│ 2421 → [0.1, -0.3, 0.7, ..., 0.2] (768 dimensions) │
│ 15698 → [-0.2, 0.5, -0.1, ..., 0.8] │
│ 9881 → [0.4, 0.2, -0.6, ..., -0.3] │
│ │
│ Result: Sequence of dense vectors for model input │
└─────────────────────────────────────────────────────────┘
Below are the top 10 System Design Case studies for this week
Billions of Queries Daily : How Google Search Actually Works
100+ Million Requests per Second : How Amazon Shopping Cart Actually Works
Serving 132+ Million Users : Scaling for Global Transit Real Time Ride Sharing Market at Uber
3 Billion Daily Users : How Youtube Actually Scales
$100000 per BTC : How Bitcoin Actually Works
$320 Billion Crypto Transactions Volume: How Coinbase Actually Works
100K Events per Second : How Uber Real-Time Surge Pricing Actually Works
Processing 2 Billion Daily Queries : How Facebook Graph Search Actually Works
7 Trillion Messages Daily : Magic Behind LinkedIn Architecture and How It Actually Works
1 Billion Tweets Daily : Magic Behind Twitter Scaling and How It Actually Works
12 Million Daily Users: Inside Slack's Real-Time Messaging Magic and How it Actually Works
3 Billion Daily Users : How Youtube Actually Scales
1.5 Billion Swipes per Day : How Tinder Matching Actually Works
500+ Million Users Daily : How Instagram Stories Actually Work
2.9 Billion Daily Active Users : How Facebook News Feed Algorithm Actually Works
20 Billion Messages Daily: How Facebook Messenger Actually Works
8+ Billion Daily Views: How Facebook's Live Video Ranking Algorithm Works
How Discord's Real-Time Chat Scales to 200+ Million Users
80 Million Photos Daily : How Instagram Achieves Real Time Photo Sharing
Serving 1 Trillion Edges in Social Graph with 1ms Read Times : How Facebook TAO works
How Lyft Handles 2x Traffic Spikes during Peak Hours with Auto scaling Infrastructure..
Diagram 2: Token Granularity Comparison
DIFFERENT TOKENIZATION APPROACHES: GRANULARITY SPECTRUM
INPUT TEXT: "unhappiness"
CHARACTER-LEVEL TOKENIZATION:
┌─────────────────────────────────────────────────────────┐
│ Tokens: ["u", "n", "h", "a", "p", "p", "i", "n", "e", "s", "s"] │
│ Count: 11 tokens │
│ │
│ Pros: │
│ • Small vocabulary size (~100 characters) │
│ • Handles any text input │
│ • Perfect for morphologically rich languages │
│ │
│ Cons: │
│ • Very long sequences │
│ • Loses semantic word boundaries │
│ • Computationally expensive │
└─────────────────────────────────────────────────────────┘
WORD-LEVEL TOKENIZATION:
┌─────────────────────────────────────────────────────────┐
│ Tokens: ["unhappiness"] │
│ Count: 1 token │
│ │
│ Pros: │
│ • Preserves semantic meaning │
│ • Short sequences │
│ • Intuitive and interpretable │
│ │
│ Cons: │
│ • Huge vocabulary (millions of words) │
│ • Cannot handle unknown words (OOV problem) │
│ • Poor generalization to new domains │
└─────────────────────────────────────────────────────────┘
SUBWORD-LEVEL TOKENIZATION (BPE):
┌─────────────────────────────────────────────────────────┐
│ Tokens: ["un", "happy", "ness"] │
│ Count: 3 tokens │
│ │
│ Pros: │
│ • Balanced vocabulary size (30K-50K tokens) │
│ • Handles unknown words via decomposition │
│ • Preserves morphological structure │
│ • Optimal length for most use cases │
│ │
│ Cons: │
│ • Requires training/learning algorithm │
│ • Can break words at arbitrary boundaries │
│ • Language-dependent performance │
└─────────────────────────────────────────────────────────┘
ADAPTIVE SUBWORD (SentencePiece):
┌─────────────────────────────────────────────────────────┐
│ Tokens: ["▁un", "happiness"] │
│ Count: 2 tokens │
│ │
│ Pros: │
│ • Language-agnostic approach │
│ • Handles spaces as regular characters │
│ • Consistent across languages │
│ • End-to-end trainable │
│ │
│ Cons: │
│ • Less intuitive token boundaries │
│ • Requires careful hyperparameter tuning │
│ • May not align with linguistic intuitions │
└─────────────────────────────────────────────────────────┘
OPTIMAL CHOICE MATRIX:
┌─────────────────────────────────────────────────────────┐
│ Use Case → Tokenization │
│ │
│ Small vocabulary needed → Character-level │
│ Multilingual models → SentencePiece │
│ Domain-specific tasks → Custom subword │
│ General language modeling → BPE/WordPiece │
│ Memory-constrained deployment → Aggressive subword │
│ High-precision tasks → Conservative subword │
└─────────────────────────────────────────────────────────┘