


[ LLM System Design #3] Large Language Models: Pre-Training LLMs: How They Actually Work - Part 3
All the technical details you need to know...
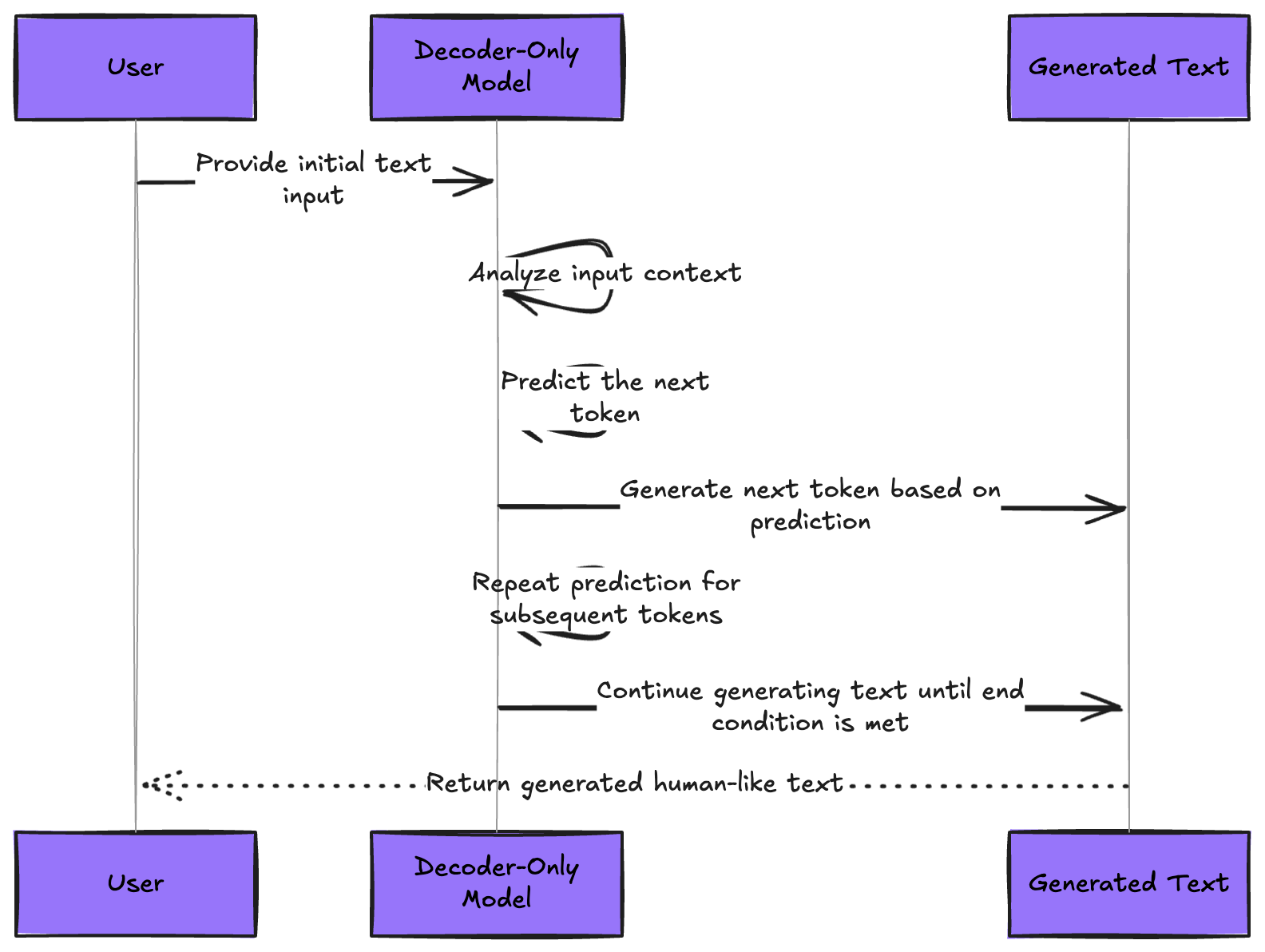
Pre-training is the foundation upon which all modern AI applications are built. By mastering these three pillars—self-supervised learning paradigms, architecture-specific pre-training tasks, and advanced optimization strategies—you gain the ability to create AI systems that can revolutionize your industry.
Read previous parts -
Understanding Transformers & Large Language Models: How They Actually Work - Part 1
Understanding Transformers & Large Language Models: How They Actually Work - Part 2
The Competitive Moat of Pre-training Expertise
Technical Differentiation: Understanding pre-training gives you capabilities that can't be easily replicated:
Custom architectures optimized for your specific domain
Efficient training pipelines that reduce costs by 10-100x
Domain expertise embedded directly into model weights
Multilingual capabilities that enable global scale
Economic Advantages: Pre-training expertise translates directly to competitive advantages:
Lower operational costs through efficient models
Faster time-to-market with proven pre-training recipes
Better performance on domain-specific tasks
Scalable solutions that improve with more data
Below are the top 10 System Design Case studies for this week
Billions of Queries Daily : How Google Search Actually Works
100+ Million Requests per Second : How Amazon Shopping Cart Actually Works
Serving 132+ Million Users : Scaling for Global Transit Real Time Ride Sharing Market at Uber
3 Billion Daily Users : How Youtube Actually Scales
$100000 per BTC : How Bitcoin Actually Works
$320 Billion Crypto Transactions Volume: How Coinbase Actually Works
100K Events per Second : How Uber Real-Time Surge Pricing Actually Works
Processing 2 Billion Daily Queries : How Facebook Graph Search Actually Works
7 Trillion Messages Daily : Magic Behind LinkedIn Architecture and How It Actually Works
1 Billion Tweets Daily : Magic Behind Twitter Scaling and How It Actually Works
12 Million Daily Users: Inside Slack's Real-Time Messaging Magic and How it Actually Works
3 Billion Daily Users : How Youtube Actually Scales
1.5 Billion Swipes per Day : How Tinder Matching Actually Works
500+ Million Users Daily : How Instagram Stories Actually Work
2.9 Billion Daily Active Users : How Facebook News Feed Algorithm Actually Works
20 Billion Messages Daily: How Facebook Messenger Actually Works
8+ Billion Daily Views: How Facebook's Live Video Ranking Algorithm Works
How Discord's Real-Time Chat Scales to 200+ Million Users
80 Million Photos Daily : How Instagram Achieves Real Time Photo Sharing
Serving 1 Trillion Edges in Social Graph with 1ms Read Times : How Facebook TAO works
How Lyft Handles 2x Traffic Spikes during Peak Hours with Auto scaling Infrastructure..
Strategic Positioning: Organizations with pre-training capabilities can:
Create foundation models that power multiple products
Adapt quickly to new domains and languages
Build moats through proprietary training data
Lead innovation in their specific industry
The Paradigm Shifts Ahead
From General to Specialized: The future belongs to domain-specific foundation models that outperform general models in specialized areas:
Medical AI: Models pre-trained on clinical literature and patient data
Legal AI: Models that understand case law and regulatory frameworks
Scientific AI: Models trained on research papers and experimental data
Financial AI: Models that comprehend market dynamics and economic patterns
From Static to Dynamic: Pre-training is evolving from one-time events to continuous processes:
Streaming pre-training: Models that learn from real-time data
Adaptive architectures: Systems that modify their structure based on new information
Personalized models: AI that adapts to individual users and contexts
Federated pre-training: Collaborative training across organizations while preserving privacy
From Unimodal to Multimodal: Diagram 3: Multi-lingual Model Architecture
MULTILINGUAL PRE-TRAINING CHALLENGES:
LANGUAGE IMBALANCE:
English: ████████████████████████ (70% of data)
Chinese: ██████████ (15% of data)
Spanish: ████ (5% of data)
French: ███ (3% of data)
German: ██ (2% of data)
Others: █████ (5% of data)
SOLUTION 1: BALANCED SAMPLING
┌─────────────────────────────────────┐
│ Original sampling → Balanced │
│ English: 70% → 30% │
│ Others: 30% → 70% (upsampled) │
│ Result: Better multilingual balance │
└─────────────────────────────────────┘
SOLUTION 2: LANGUAGE-SPECIFIC ADAPTERS
┌─────────────────────────────────────┐
│ SHARED TRANSFORMER │
│ ┌─────────────────────────────┐ │
│ │ Universal Language │ │
│ │ Representations │ │
│ └─────────────────────────────┘ │
│ ↓ │
│ ┌─────┬─────┬─────┬─────┬─────┐ │
│ │ EN │ ZH │ ES │ FR │ DE │ │
│ │Adapt│Adapt│Adapt│Adapt│Adapt│ │
│ └─────┴─────┴─────┴─────┴─────┘ │
└─────────────────────────────────────┘
CROSS-LINGUAL TRANSFER:
Training Languages: EN, ZH, ES, FR, DE, JA, KO, ...
Zero-shot Languages: Hindi, Arabic, Swahili, ...
Performance: 60-80% of supervised performance
Benefits:
✓ Single model handles 100+ languages
✓ Cross-lingual knowledge transfer
✓ Cost-effective for global applications
✓ Enables low-resource language support
Diagram 4: Model Compression Techniques
COMPRESSION STRATEGY COMPARISON:
Original BERT-Large (340M parameters):
┌─────────────────────────────────────────┐
│ ████████████████████████████████████ │ 100% size
│ Performance: 100% (baseline) │
│ Inference: 100ms │
│ Memory: 1.3GB │
└─────────────────────────────────────────┘
1. KNOWLEDGE DISTILLATION:
┌─────────────────────────────────────────┐
│ ████████ │ 25% size (80M params)
│ Performance: 97% of original │
│ Inference: 25ms (-75%) │
│ Memory: 320MB (-75%) │
└─────────────────────────────────────────┘
2. PRUNING (Structured):
┌─────────────────────────────────────────┐
│ ████████████████████ │ 50% size (170M params)
│ Performance: 98% of original │
│ Inference: 50ms (-50%) │
│ Memory: 650MB (-50%) │
└─────────────────────────────────────────┘
3. QUANTIZATION (INT8):
┌─────────────────────────────────────────┐
│ ████████████████████████████████████ │ 100% params, 25% precision
│ Performance: 99% of original │
│ Inference: 70ms (-30%) │
│ Memory: 325MB (-75%) │
└─────────────────────────────────────────┘
4. COMBINATION (Distill + Quantize):
┌─────────────────────────────────────────┐
│ ████████ │ 25% size, 25% precision
│ Performance: 95% of original │
│ Inference: 18ms (-82%) │
│ Memory: 80MB (-94%) │
└─────────────────────────────────────────┘
DEPLOYMENT TARGET RECOMMENDATIONS:
Mobile/Edge: Combination approach
Cloud/Server: Quantization only
High-accuracy: Pruning only
Research: Original model