
[Important LLM System Design #5] Training the Encoder-Decoder Model - Orchestrating Intelligence: How They Actually Work - Part 5
All the technical details you need to know...
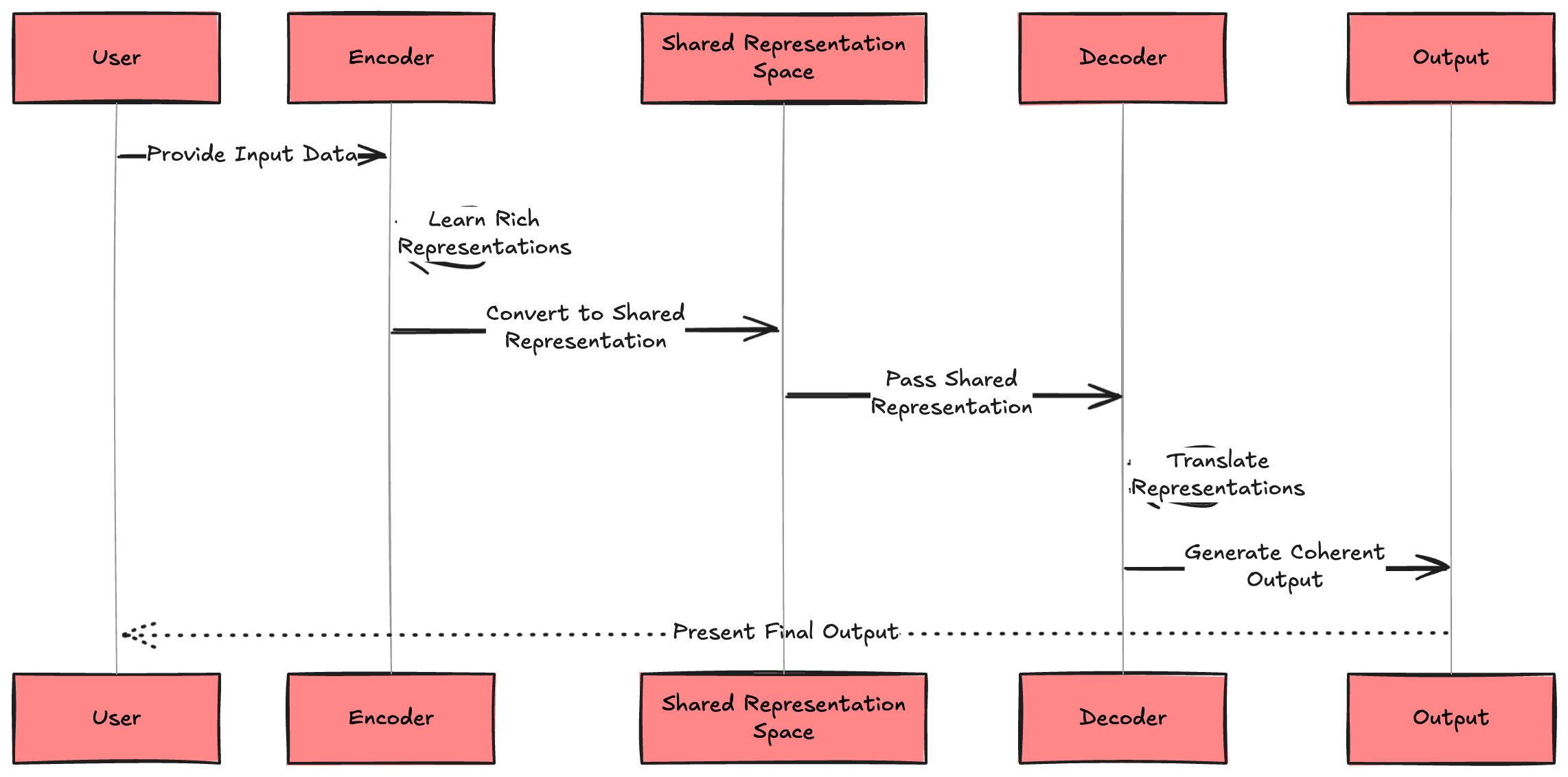
The decoder's autoregressive nature—generating one token at a time based on all previous tokens—introduces unique challenges. Each generation step must maintain consistency with everything that came before while making intelligent predictions about what should come next.
Read previous parts -
Understanding Transformers & Large Language Models: How They Actually Work - Part 1
Understanding Transformers & Large Language Models: How They Actually Work - Part 2
[LLM System Design #3] Large Language Models: Pre-Training LLMs: How They Actually Work - Part 3
Diagram 1: Decoder Construction Architecture
DECODER ARCHITECTURE BLUEPRINT
GENERATION SETUP:
┌─────────────────────────────────────┐
│ Prompt: "Write a story about..." │
│ ↓ │
│ Tokenization: [101][5039][64]... │
│ ↓ │
│ Initial Context: [batch×seq×768] │
└─────────────────────────────────────┘
DECODER LAYER STACK (×N):
┌─────────────────────────────────────┐
│ DECODER LAYER │
│ ┌─────────────────────────────────┐ │
│ │ MASKED SELF-ATTENTION │ │
│ │ │ │
│ │ Causal Mask (Lower Triangular): │ │
│ │ ✓ ✗ ✗ ✗ (Position 1) │ │
│ │ ✓ ✓ ✗ ✗ (Position 2) │ │
│ │ ✓ ✓ ✓ ✗ (Position 3) │ │
│ │ ✓ ✓ ✓ ✓ (Position 4) │ │
│ │ │ │
│ │ Prevents future information │ │
│ │ leakage during training │ │
│ └─────────────────────────────────┘ │
│ ↓ │
│ ┌─────────────────────────────────┐ │
│ │ RESIDUAL + LAYER NORM │ │
│ └─────────────────────────────────┘ │
│ ↓ │
│ ┌─────────────────────────────────┐ │
│ │ FEED-FORWARD NETWORK │ │
│ │ W₂(ReLU(W₁x + b₁)) + b₂ │ │
│ └─────────────────────────────────┘ │
│ ↓ │
│ ┌─────────────────────────────────┐ │
│ │ RESIDUAL + LAYER NORM │ │
│ └─────────────────────────────────┘ │
└─────────────────────────────────────┘
GENERATION HEAD:
┌─────────────────────────────────────┐
│ Hidden States [batch×seq×hidden] │
│ ↓ │
│ Linear Projection [hidden×vocab] │
│ ↓ │
│ Logits [batch×seq×vocab_size] │
│ ↓ │
│ Softmax → Probability Distribution │
│ ↓ │
│ Sampling Strategy: │
│ • Greedy: argmax(probs) │
│ • Top-k: sample from top k │
│ • Top-p: nucleus sampling │
│ • Temperature: control randomness │
└─────────────────────────────────────┘
Diagram 2: Causal Masking Implementation
CAUSAL ATTENTION MECHANICS
STEP-BY-STEP GENERATION:
Step 1: Initial Context
┌─────────────────────────────────────┐
│ Input: "The future of AI" │
│ Tokens: [The][future][of][AI] │
│ │
│ Attention Matrix (4×4): │
│ The fut of AI │
│ The ✓ ✗ ✗ ✗ │
│ fut ✓ ✓ ✗ ✗ │
│ of ✓ ✓ ✓ ✗ │
│ AI ✓ ✓ ✓ ✓ │
│ │
│ Next token prediction at position 5 │
└─────────────────────────────────────┘
Step 2: Add Generated Token
┌─────────────────────────────────────┐
│ Updated: "The future of AI will" │
│ Tokens: [The][future][of][AI][will] │
│ │
│ Attention Matrix (5×5): │
│ The fut of AI will │
│ The ✓ ✗ ✗ ✗ ✗ │
│ fut ✓ ✓ ✗ ✗ ✗ │
│ of ✓ ✓ ✓ ✗ ✗ │
│ AI ✓ ✓ ✓ ✓ ✗ │
│ will ✓ ✓ ✓ ✓ ✓ │
│ │
│ Next token prediction at position 6 │
└─────────────────────────────────────┘
MASK IMPLEMENTATION:
┌─────────────────────────────────────┐
│ def create_causal_mask(seq_len): │
│ mask = torch.tril( │
│ torch.ones(seq_len, seq_len)│
│ ) │
│ mask = mask.masked_fill( │
│ mask == 0, float('-inf') │
│ ) │
│ return mask │
│ │
│ scores = QK^T / sqrt(d_k) │
│ scores = scores + causal_mask │
│ attention = softmax(scores) │
└─────────────────────────────────────┘
TRAINING VS INFERENCE:
┌─────────────────────────────────────┐
│ Training (Teacher Forcing): │
│ • All positions computed in parallel│
│ • Ground truth provided as input │
│ • Faster but creates exposure bias │
│ │
│ Inference (Autoregressive): │
│ • Sequential generation required │
│ • Model uses own predictions │
│ • Slower but matches real usage │
└─────────────────────────────────────┘
Diagram 3: Generation Strategies Comparison
SAMPLING STRATEGIES FOR TEXT GENERATION
INPUT: "The weather today is"
DECODER OUTPUT LOGITS: [vocab_size] vector
GREEDY DECODING:
┌─────────────────────────────────────┐
│ Top Predictions: │
│ "sunny": 0.35 ← Selected │
│ "cloudy": 0.28 │
│ "rainy": 0.15 │
│ "beautiful": 0.12 │
│ "perfect": 0.10 │
│ │
│ Always picks highest probability │
│ Result: Deterministic, safe │
│ Problem: Repetitive, boring │
└─────────────────────────────────────┘
TOP-K SAMPLING (k=3):
┌─────────────────────────────────────┐
│ Candidate Pool: │
│ "sunny": 0.35 ← Renormalized │
│ "cloudy": 0.28 ← to sum to 1.0 │
│ "rainy": 0.15 ← (0.48, 0.36, 0.16)│
│ [Other tokens ignored] │
│ │
│ Sample from: {sunny, cloudy, rainy} │
│ Result: More diverse │
│ Problem: Fixed k may be suboptimal │
└─────────────────────────────────────┘
TOP-P (NUCLEUS) SAMPLING (p=0.8):
┌─────────────────────────────────────┐
│ Cumulative Probabilities: │
│ "sunny": 0.35 (cum: 0.35) │
│ "cloudy": 0.28 (cum: 0.63) │
│ "rainy": 0.15 (cum: 0.78) ← cutoff │
│ "beautiful": 0.12 (cum: 0.90) │
│ │
│ Include tokens until cum_prob > 0.8 │
│ Dynamic vocabulary size │
│ Result: Adaptive diversity │
└─────────────────────────────────────┘
TEMPERATURE SCALING:
┌─────────────────────────────────────┐
│ Original: [2.1, 1.8, 1.2, 0.9] │
│ │
│ T=0.5 (Conservative): │
│ [4.2, 3.6, 2.4, 1.8] → Sharp dist │
│ Result: More focused, predictable │
│ │
│ T=1.0 (Normal): │
│ [2.1, 1.8, 1.2, 0.9] → Unchanged │
│ │
│ T=2.0 (Creative): │
│ [1.05, 0.9, 0.6, 0.45] → Flat dist │
│ Result: More random, creative │
└─────────────────────────────────────┘
BEAM SEARCH (beam_size=3):
┌─────────────────────────────────────┐
│ Maintains multiple hypotheses: │
│ │
│ Beam 1: "sunny and warm" │
│ Score: -0.5 (log probability) │
│ │
│ Beam 2: "cloudy but pleasant" │
│ Score: -0.7 │
│ │
│ Beam 3: "rainy and cool" │
│ Score: -0.9 │
│ │
│ Selects best overall sequence │
│ Result: Higher quality, coherent │
│ Cost: Increased computation │
└─────────────────────────────────────┘
The choice of generation strategy dramatically impacts both the quality and character of the output. Understanding these trade-offs allows you to tune your decoder for specific applications—conservative for factual content, creative for storytelling, or balanced for general conversation.
Advanced Decoder Techniques
Repetition Penalty: Modify probabilities of previously generated tokens to encourage diversity and reduce repetitive loops that can plague autoregressive models. This technique dynamically adjusts the likelihood of repeating recent tokens.
Length Normalization: Adjust scores by sequence length to prevent bias toward shorter sequences, particularly important for tasks like machine translation where output length varies significantly.
Constrained Generation: Force the model to include or avoid specific tokens, useful for controllable generation and safety filtering. This can be implemented through modified beam search or rejection sampling.
Contrastive Search: A recent technique that balances model confidence with diversity, producing more coherent and less repetitive text than traditional sampling methods.
Below are the top 10 System Design Case studies for this week
Billions of Queries Daily : How Google Search Actually Works
100+ Million Requests per Second : How Amazon Shopping Cart Actually Works
Serving 132+ Million Users : Scaling for Global Transit Real Time Ride Sharing Market at Uber
3 Billion Daily Users : How Youtube Actually Scales
$100000 per BTC : How Bitcoin Actually Works
$320 Billion Crypto Transactions Volume: How Coinbase Actually Works
100K Events per Second : How Uber Real-Time Surge Pricing Actually Works
Processing 2 Billion Daily Queries : How Facebook Graph Search Actually Works
7 Trillion Messages Daily : Magic Behind LinkedIn Architecture and How It Actually Works
1 Billion Tweets Daily : Magic Behind Twitter Scaling and How It Actually Works
12 Million Daily Users: Inside Slack's Real-Time Messaging Magic and How it Actually Works
3 Billion Daily Users : How Youtube Actually Scales
1.5 Billion Swipes per Day : How Tinder Matching Actually Works
500+ Million Users Daily : How Instagram Stories Actually Work
2.9 Billion Daily Active Users : How Facebook News Feed Algorithm Actually Works
20 Billion Messages Daily: How Facebook Messenger Actually Works
8+ Billion Daily Views: How Facebook's Live Video Ranking Algorithm Works
How Discord's Real-Time Chat Scales to 200+ Million Users
80 Million Photos Daily : How Instagram Achieves Real Time Photo Sharing
Serving 1 Trillion Edges in Social Graph with 1ms Read Times : How Facebook TAO works
How Lyft Handles 2x Traffic Spikes during Peak Hours with Auto scaling Infrastructure..