
[Important LLM System Design #4] Heart of Large Language Models: Encoder and Decoder: How They Actually Work - Part 4
All the technical details you need to know...
Part 1: The Encoder - The Master of Understanding
What Is an Encoder?
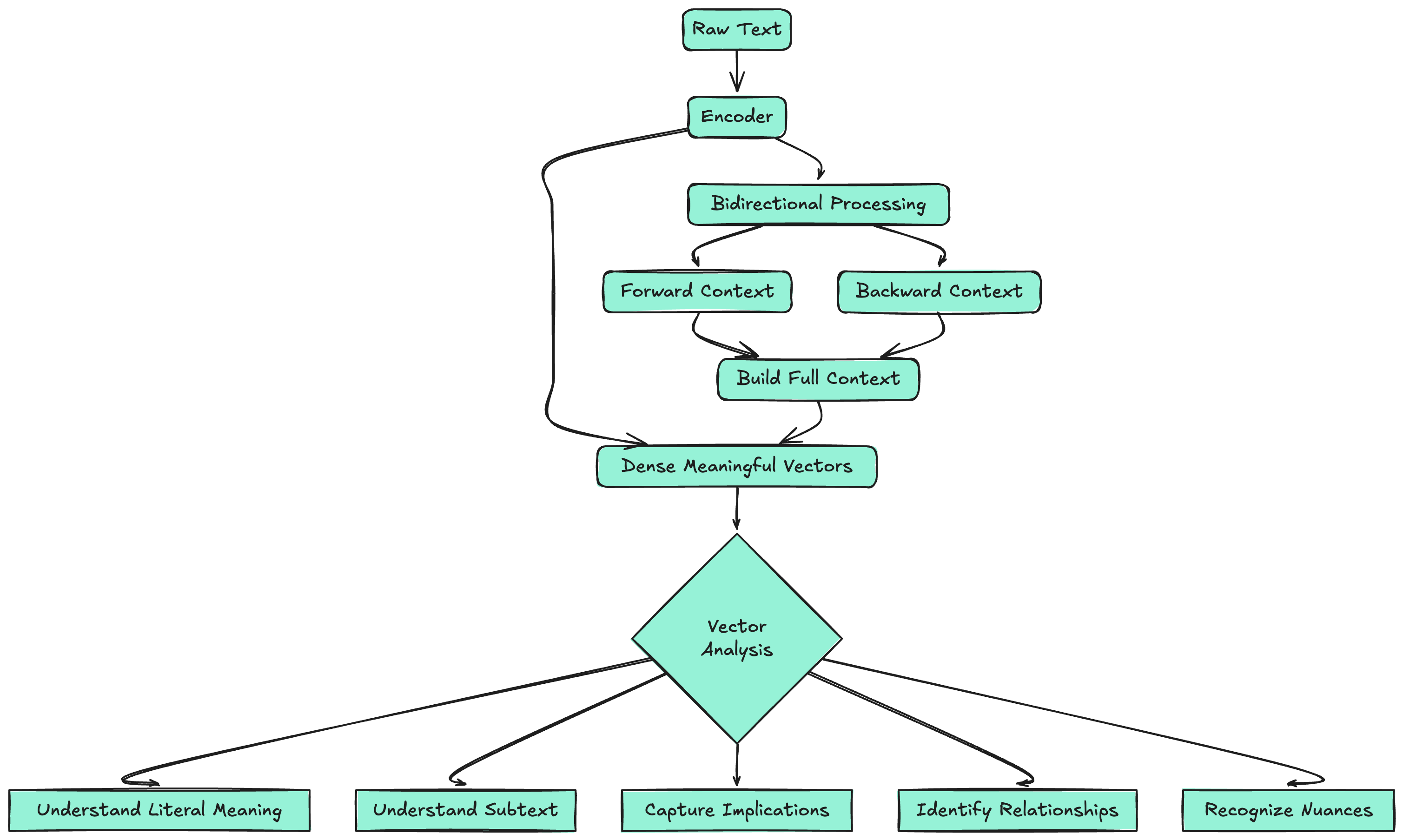
Think of an Encoder as the world's most sophisticated reading comprehension system. While humans read text sequentially, word by word, an Encoder sees the entire text simultaneously and builds a rich, multi-dimensional understanding of every element in context.
The Encoder's job is representation learning—transforming raw text into dense, meaningful vectors that capture not just what each word means, but how it relates to every other word in the sequence. It's like having a brilliant analyst who can read a document and instantly understand not just the literal meaning, but the subtext, implications, relationships, and nuances.
Core Principle: Encoders are bidirectional—they can look both forward and backward in the sequence, building representations that incorporate full context from both directions.
Read previous parts -
Understanding Transformers & Large Language Models: How They Actually Work - Part 1
Understanding Transformers & Large Language Models: How They Actually Work - Part 2
[LLM System Design #3] Large Language Models: Pre-Training LLMs: How They Actually Work - Part 3
Diagram 1: Encoder Architecture Deep Dive
INPUT: "The quick brown fox jumps over the lazy dog"
┌─────────────────────────────────────────────────────────┐
│ INPUT LAYER │
│ [The] [quick] [brown] [fox] [jumps] [over] [the] [lazy] [dog] │
│ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ │
│ E₁ E₂ E₃ E₄ E₅ E₆ E₇ E₈ E₉ │
│ + + + + + + + + + │
│ P₁ P₂ P₃ P₄ P₅ P₆ P₇ P₈ P₉ │
└─────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────┐
│ ENCODER LAYER 1 │
│ ┌─────────────────────────────────────────────────┐ │
│ │ MULTI-HEAD SELF-ATTENTION │ │
│ │ │ │
│ │ Head 1: Syntactic Relations │ │
│ │ "fox" ←→ "jumps" (subject-verb) │ │
│ │ "quick brown" ←→ "fox" (adjective-noun) │ │
│ │ │ │
│ │ Head 2: Semantic Understanding │ │
│ │ "fox" ←→ "dog" (animal category) │ │
│ │ "jumps over" ←→ spatial relationship │ │
│ │ │ │
│ │ Head 3: Discourse Structure │ │
│ │ "The...fox" ←→ "the...dog" (subject/object) │ │
│ └─────────────────────────────────────────────────┘ │
│ ↓ │
│ ┌─────────────────────────────────────────────────┐ │
│ │ ADD & NORM │ │
│ │ Residual Connection + Layer Norm │ │
│ └─────────────────────────────────────────────────┘ │
│ ↓ │
│ ┌─────────────────────────────────────────────────┐ │
│ │ FEED-FORWARD NETWORK │ │
│ │ │ │
│ │ Input → Linear(2048) → ReLU → Linear(512) │ │
│ │ Point-wise processing for each position │ │
│ └─────────────────────────────────────────────────┘ │
│ ↓ │
│ ┌─────────────────────────────────────────────────┐ │
│ │ ADD & NORM │ │
│ └─────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────┘
↓
[Repeat for Layers 2-6...]
↓
┌─────────────────────────────────────────────────────────┐
│ FINAL OUTPUT │
│ [R₁] [R₂] [R₃] [R₄] [R₅] [R₆] [R₇] [R₈] [R₉] │
│ │
│ Rich contextualized representations where: │
│ • Each R contains full sentence understanding │
│ • Relationships between all words are encoded │
│ • Semantic and syntactic information preserved │
│ • Ready for downstream tasks │
└─────────────────────────────────────────────────────────┘
Diagram 2: Bidirectional Context Flow
Traditional RNN (Sequential):
Time →
[The] → [quick] → [brown] → [fox] → [jumps]
↓ ↓ ↓ ↓ ↓
h₁ h₂ h₃ h₄ h₅
Problem: h₄ only knows about [The, quick, brown, fox]
It has NO information about [jumps, over, the, lazy, dog]
Encoder Self-Attention (Bidirectional):
┌─────────────────────────────────────┐
│ GLOBAL ATTENTION │
└─────────────────────────────────────┘
↙ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↘
[The] ←→ [quick] ←→ [brown] ←→ [fox] ←→ [jumps] ←→ [over] ←→ [the] ←→ [lazy] ←→ [dog]
↕ ↕ ↕ ↕ ↕ ↕ ↕ ↕ ↕
R₁ R₂ R₃ R₄ R₅ R₆ R₇ R₈ R₉
Advantage: R₄ ("fox") knows about ENTIRE sequence
It understands "fox" is the subject of "jumps"
AND that it's being contrasted with "dog"
Self-Attention Matrix for "fox":
Attention to: [The] [quick] [brown] [fox] [jumps] [over] [the] [lazy] [dog]
Weights: [0.05] [0.1] [0.3] [0.2] [0.25] [0.02] [0.03] [0.02] [0.03]
"fox" pays most attention to:
- "brown" (0.3) - its direct modifier
- "jumps" (0.25) - the action it performs
- itself (0.2) - self-reference
- "quick" (0.1) - another modifier
Below are the top 10 System Design Case studies for this week
Billions of Queries Daily : How Google Search Actually Works
100+ Million Requests per Second : How Amazon Shopping Cart Actually Works
Serving 132+ Million Users : Scaling for Global Transit Real Time Ride Sharing Market at Uber
3 Billion Daily Users : How Youtube Actually Scales
$100000 per BTC : How Bitcoin Actually Works
$320 Billion Crypto Transactions Volume: How Coinbase Actually Works
100K Events per Second : How Uber Real-Time Surge Pricing Actually Works
Processing 2 Billion Daily Queries : How Facebook Graph Search Actually Works
7 Trillion Messages Daily : Magic Behind LinkedIn Architecture and How It Actually Works
1 Billion Tweets Daily : Magic Behind Twitter Scaling and How It Actually Works
12 Million Daily Users: Inside Slack's Real-Time Messaging Magic and How it Actually Works
3 Billion Daily Users : How Youtube Actually Scales
1.5 Billion Swipes per Day : How Tinder Matching Actually Works
500+ Million Users Daily : How Instagram Stories Actually Work
2.9 Billion Daily Active Users : How Facebook News Feed Algorithm Actually Works
20 Billion Messages Daily: How Facebook Messenger Actually Works
8+ Billion Daily Views: How Facebook's Live Video Ranking Algorithm Works
How Discord's Real-Time Chat Scales to 200+ Million Users
80 Million Photos Daily : How Instagram Achieves Real Time Photo Sharing
Serving 1 Trillion Edges in Social Graph with 1ms Read Times : How Facebook TAO works
How Lyft Handles 2x Traffic Spikes during Peak Hours with Auto scaling Infrastructure..
Diagram 3: Multi-Head Attention Specialization in Encoders
Input: "The company's AI model achieved breakthrough performance"
HEAD 1: Syntactic Structure Analysis
┌─────────────────────────────────────────────────────────┐
│ Attention Pattern: Grammatical relationships │
│ │
│ "company's" → "model" (possessive relationship) │
│ "AI" → "model" (noun-noun compound) │
│ "model" → "achieved" (subject-verb) │
│ "achieved" → "performance" (verb-object) │
│ "breakthrough" → "performance" (adjective-noun) │
│ │
│ Output: Grammatical structure understanding │
└─────────────────────────────────────────────────────────┘
HEAD 2: Semantic Relationship Mapping
┌─────────────────────────────────────────────────────────┐
│ Attention Pattern: Meaning relationships │
│ │
│ "AI" ←→ "model" (technology category) │
│ "achieved" ←→ "breakthrough" (accomplishment) │
│ "breakthrough" ←→ "performance" (quality measure) │
│ "company's" ←→ "AI model" (ownership) │
│ │
│ Output: Conceptual understanding │
└─────────────────────────────────────────────────────────┘
HEAD 3: Contextual Importance Weighting
┌─────────────────────────────────────────────────────────┐
│ Attention Pattern: Information importance │
│ │
│ High attention: "breakthrough", "AI", "performance" │
│ Medium attention: "achieved", "model" │
│ Low attention: "The", "company's" │
│ │
│ Output: Key information extraction │
└─────────────────────────────────────────────────────────┘
COMBINED MULTI-HEAD OUTPUT:
┌─────────────────────────────────────────────────────────┐
│ Rich Representation Vector for each token that contains: │
│ │
│ • Grammatical role and relationships │
│ • Semantic meaning and associations │
│ • Relative importance in context │
│ • Position and structural information │
│ │
│ Result: Each word understands its complete context │
└─────────────────────────────────────────────────────────┘
Attention Score Visualization:
Token: [The] [company's] [AI] [model] [achieved] [breakthrough] [performance]
Avg Score: [0.02] [0.12] [0.18] [0.25] [0.15] [0.20] [0.08]
Most important: "model" (0.25) - central entity
High importance: "breakthrough" (0.20), "AI" (0.18) - key descriptors
Moderate: "achieved" (0.15), "company's" (0.12) - structural elements
Low: "performance" (0.08), "The" (0.02) - supporting words
Why Encoders Are Revolutionary
1. Bidirectional Understanding: Unlike sequential models, Encoders see the complete context from both directions, enabling unprecedented comprehension depth.
2. Parallel Processing: All positions are processed simultaneously, making training dramatically faster than sequential approaches.
3. Rich Contextual Representations: Each token's representation contains information about its relationship to every other token in the sequence.
4. Task Agnostic: The same encoder architecture can be used for classification, similarity matching, information extraction, and more.
5. Transfer Learning Powerhouse: Pre-trained encoders like BERT capture general language understanding that transfers beautifully to specific tasks.