


[System Design Tech Case Study Pulse #2] How Lyft Handles 2x Traffic Spikes during Peak Hours with Auto scaling Infrastructure..
Tech you must know....


Hi All,
Lyft's auto scaling infrastructure is a marvel of modern cloud engineering, capable of seamlessly handling 2x traffic spikes during peak hours. This robust system forms the backbone of Lyft's ability to maintain high performance and reliability, even under rapidly changing demand.
Read how to answer Design Lyft
We will continue to add a growing amount of system design, projects and ML/AI content. Ignito ( this publication) urgently needs you and your support (else Ignito will shut down). If you like Ignito publication and my work please support with some ( even a small amount is good) help/donation : Link
In this post, I’ll dive deep into how this system works, exploring the key components, technologies, and processes that enable such dynamic scalability.
System Overview
Before I delve into the auto scaling architecture, let's look at some key metrics of Lyft's system:
Daily active users: 20+ million
Peak requests per second: Over 100,000
Normal to peak traffic ratio: 2:1
Supported cities: 600+
Microservices: 1000+
Kubernetes pods: 100,000+
Auto scaling response time: < 30 seconds
Infrastructure provisioning time: < 2 minutes
System availability during traffic spikes: 99.99%
Average request latency increase during spikes: < 10%
Cloud regions utilized: 3 main, 2 backup
Ignito System Design Youtube Channel
System Design Github - Link
Learn system design pulses -
[System Design Pulse #3] THE theorem of System Design and why you MUST know it - Brewer theorem
[System Design Pulse #4] How Distributed Message Queues Work?
[System Design Pulse #5] Breaking It Down: The Magic Behind Microservices Architecture
[System Design Pulse #6] Why Availability Patterns Are So Crucial in System Design?
[System Design Pulse #7] How Consistency Patterns helps Design Robust and Efficient Systems?
[System Design Pulse #9] Why these Key Components are Crucial for System Design.
How Process Works —

User interacts with the Lyft App, generating traffic.
Global Load Balancer distributes requests across data centers.
API Gateway handles initial request processing.
Traffic Ingress Service analyzes incoming traffic in real-time.
Forecasting Engine predicts future traffic patterns.
Capacity Planning Service determines resource needs.
Kubernetes Cluster manages the application infrastructure:
Cluster Autoscaler handles node-level scaling.
Horizontal Pod Autoscaler manages service-level scaling.
Microservices handle specific functionalities (ride matching, pricing, etc.).
Custom Resource Autoscaler manages scaling for databases, caches, and queues.
Lyft's auto scaling infrastructure -

1. Real time Traffic Analysis
1. The Traffic Ingress Service continuously monitors incoming requests:
Tracks request rates across all endpoints
Analyzes traffic patterns and user behavior
Identifies anomalies and sudden spikes
2. The Load Balancing Layer provides crucial metrics:
Measures server response times and error rates
Tracks connection pool utilization
Reports on geographic distribution of traffic
Key metrics for this process:
Metric collection interval: Every 5 seconds
Anomaly detection time: < 10 seconds
Traffic pattern analysis latency: < 30 seconds
Predictive Analytics

1. The Forecasting Engine anticipates future traffic patterns:
Utilizes historical data and machine learning models
Considers factors like time of day, weather, and special events
Generates short term (minutes) and long term (hours) predictions
2. The Capacity Planning Service uses these predictions to prepare:
Estimates required resources for anticipated traffic
Triggers proactive scaling actions
Adjusts scaling thresholds dynamically
Prediction accuracy metrics:
Short term prediction accuracy: Within 10% for 95% of cases
Long term prediction accuracy: Within 20% for 90% of cases
Proactive scaling trigger time: 5 15 minutes before anticipated spike
2. Auto scaling Architecture
Lyft's auto scaling system is designed for rapid response and fine grained control:
1. The Kubernetes Cluster Autoscaler manages node level scaling:
Monitors pod scheduling and resource utilization
Adds or removes nodes based on demand
Optimizes for cost efficiency and performance
2. The Horizontal Pod Autoscaler handles service level scaling:
Adjusts the number of pods for each service
Uses custom metrics beyond CPU/memory (e.g., request rate, queue length)
Implements different scaling policies for various service types
3. The Custom Resource Autoscaler manages Lyft specific resources:
Scales databases, caches, and message queues
Implements gradual scaling to prevent thundering herd problems
Ensures data consistency during scaling operations
Auto scaling performance metrics:
Node provisioning time: < 90 seconds
Pod scaling time: < 30 seconds
Custom resource scaling time: < 2 minutes
Scaling decision time: < 10 seconds

3. Intelligent Load Distribution
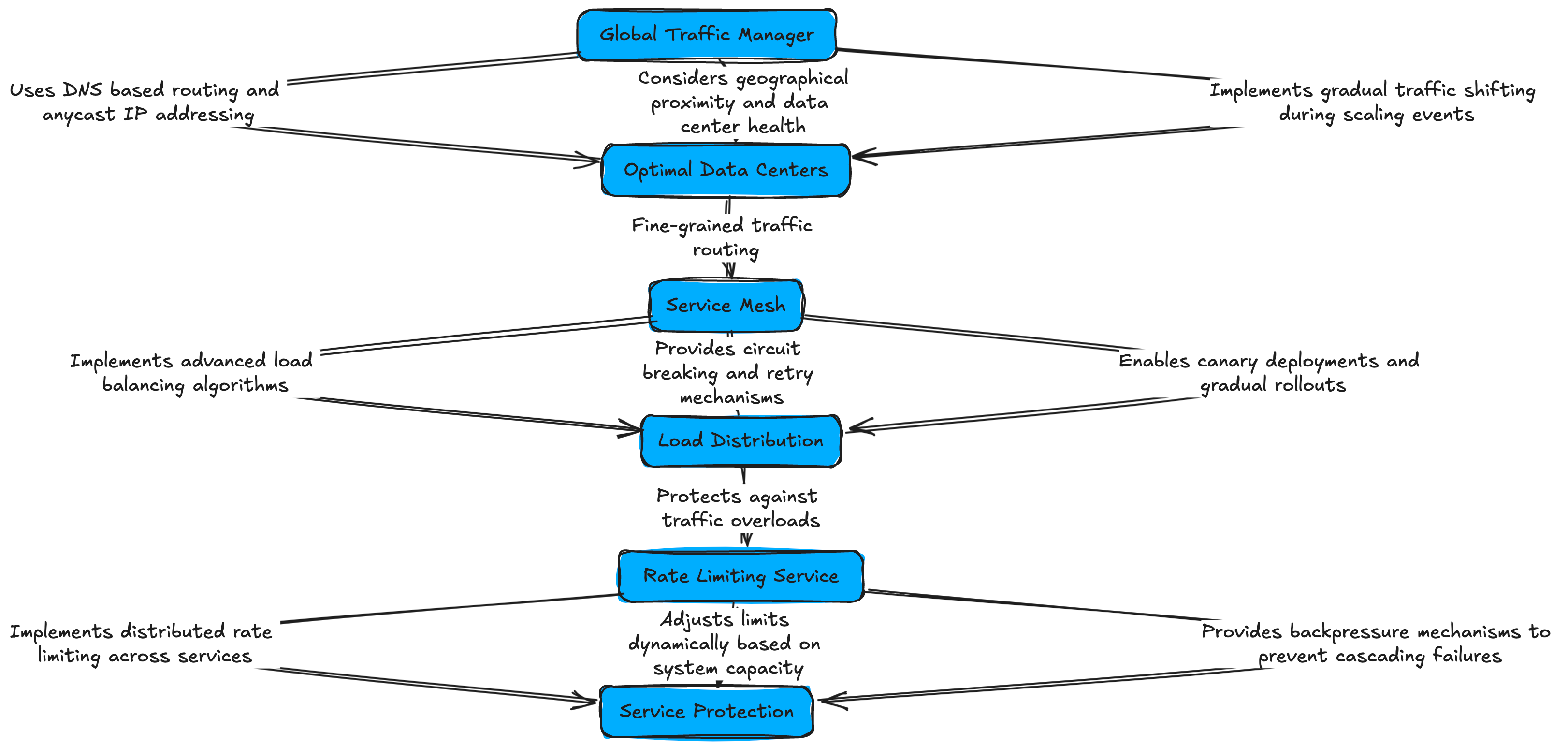
As the system scales, efficient load distribution becomes crucial:
1. The Global Traffic Manager directs users to optimal data centers:
Uses DNS based routing and anycast IP addressing
Considers geographical proximity and data center health
Implements gradual traffic shifting during scaling events
2. The Service Mesh (based on Envoy) handles fine grained traffic routing:
Implements advanced load balancing algorithms (least request, ring hash)
Provides circuit breaking and retry mechanisms
Enables canary deployments and gradual rollouts
3. The Rate Limiting Service protects against traffic overloads:
Implements distributed rate limiting across services
Adjusts limits dynamically based on system capacity
Provides backpressure mechanisms to prevent cascading failures
Load distribution metrics:
Global routing decision time: < 50ms
Service to service request latency: < 10ms
Rate limiting decision time: < 5ms
Load balancing efficiency: < 5% variation in load across instances
4. Data Management and Consistency

Maintaining data consistency during rapid scaling is a significant challenge:
1. The Distributed Caching System ensures fast data access:
Implements multi level caching (local, regional, global)
Uses consistent hashing for cache key distribution
Provides automatic cache population and invalidation
2. The Database Auto scaler manages database performance:
Implements read replica auto scaling for high traffic periods
Manages connection pools dynamically
Provides query caching and optimization on the fly
3. The State Management Service handles stateful operations:
Implements distributed locking for critical operations
Manages session stickiness when required
Provides a consistent view of system state across scaling events
Data management metrics:
Cache hit ratio: > 95% during traffic spikes
Database read replica spin up time: < 3 minutes
State convergence time after scaling: < 30 seconds
Data consistency guarantee: 99.99% during 2x traffic spikes
Behind the Scenes: Infrastructure and Optimization
To handle 2x traffic spikes efficiently, Lyft's infrastructure incorporates several advanced techniques:
1. Container Orchestration :
Utilizes Kubernetes for container management and orchestration
Implements custom schedulers for domain specific requirements
Achieves 95% resource utilization during peak times
2. Infrastructure as Code :
Uses tools like Terraform and Ansible for infrastructure provisioning
Implements GitOps practices for infrastructure changes
Enables rapid, version controlled infrastructure updates
3. Chaos Engineering :
Regularly simulates traffic spikes and component failures
Identifies bottlenecks and single points of failure
Improves system resilience through continuous testing
4. Performance Optimization :
Implements code level optimizations (e.g., asynchronous processing, caching)
Utilizes profiling tools to identify and resolve bottlenecks
Achieves 30% improvement in request throughput through ongoing optimizations
5. Cost Management :
Implements spot instance usage for non critical workloads
Uses automated cost allocation and tracking
Achieves 40% cost reduction compared to static provisioning
Infrastructure metrics:
Container startup time: < 5 seconds
Infrastructure provisioning accuracy: 99.99%
Chaos test frequency: Weekly for critical systems
Cost per request: Reduced by 35% during traffic spikes
Handling Scale and Efficiency -
To manage 2x traffic spikes with auto scaling infrastructure, Lyft employs -
1. Predictive Auto scaling :
Uses machine learning to forecast traffic patterns
Initiates scaling actions proactively
Reduces reactive scaling needs by 60%
2. Multi dimensional Scaling :
Scales not just horizontally, but also vertically and diagonally
Optimizes instance types based on workload characteristics
Achieves 25% better resource utilization compared to simple horizontal scaling
3. Granular Service Scaling :
Implements per service scaling policies
Uses custom metrics for scaling decisions (e.g., queue length, request complexity)
Reduces over provisioning by 40% compared to uniform scaling
4. Stateless Service Architecture :
Designs 95% of services to be stateless
Utilizes distributed caching and session stores
Enables near linear scalability for most system components
5. Adaptive Load Shedding :
Implements intelligent request prioritization during peaks
Gracefully degrades non critical features under extreme load
Maintains core functionality even under 3x unexpected traffic spikes
6. Real time Performance Tuning :
Dynamically adjusts system parameters (e.g., thread pools, connection limits)
Implements automated database query optimization
Achieves 20% latency reduction during traffic spikes
If you liked this article, like and share.
Learn real world system design —
[Tuesday Engineering Bytes] How Netflix handles millions of memberships efficiently?
[Friday Engineering Bytes] The Billion-Dollar Question - What's My ETA? How Uber Calculates ETA...
[Saturday Engineering Bytes] What happens Once You Press Play button on Netflix..
[Monday Engineering Bytes] FAANG level - How to Write Production Ready Code ?
[Friday Engineering Bytes] At Amazon How 310 Million Users Experience Lightning-Fast Load Times
[Tuesday Engineering Bytes] How PayPal Manages Over 400 Million Active Accounts Seamlessly?
Master System Design
More system design case studies coming soon! Follow - Link
Things you must know in System Design -
System design basics : https://bit.ly/3SuUR0Y
Horizontal and vertical scaling : https://bit.ly/3slq5xh
Load balancing and Message queues: https://bit.ly/3sp0FP4
High level design and low level design, Consistent Hashing, Monolithic and Microservices architecture : https://bit.ly/3DnEfEm
Caching, Indexing, Proxies : https://bit.ly/3SvyVDc
Networking, How Browsers work, Content Network Delivery ( CDN) : https://bit.ly/3TOHQRb
Database Sharding, CAP Theorem, Database schema Design : https://bit.ly/3CZtfLN
Concurrency, API, Components + OOP + Abstraction : https://bit.ly/3sqQrhj
Estimation and Planning, Performance : https://bit.ly/3z9dSPN
Map Reduce, Patterns and Microservices : https://bit.ly/3zcsfmv
SQL vs NoSQL and Cloud : https://bit.ly/3z8Aa49
Github for System Design Interviews with Case Studies
Master Data Structures and Algorithms
Topics that are important in Data Structures and Algorithms : https://bit.ly/3EAud36
Complexity Analysis : https://bit.ly/3fSMChP
Backtracking : https://bit.ly/3TazwL3
Sliding Window : https://bit.ly/3ywJezP
Greedy Technique : https://bit.ly/3rMgb7m
Two pointer Technique : https://bit.ly/3yvVqRc
1- D Dynamic Programming : https://bit.ly/3COFU5s
Arrays : https://bit.ly/3MqxuEK
Linked List : https://bit.ly/3rIwBxI
Strings : https://bit.ly/3MmIH96
Stack : https://bit.ly/3ToikSB
Queues : https://bit.ly/3yHSssX
Hash Table/Hashing : https://bit.ly/3ew8oYm
Binary Search : https://bit.ly/3yK9R4l
Trees : https://bit.ly/3g1og5u
Heap/Priority Queue : https://bit.ly/3rZb9EI
Divide and Conquer Technique : https://bit.ly/3esYWF3
Recursion : https://bit.ly/3yvPbwN
Curated Question List 1 : https://bit.ly/3ggSDFq
Curated Question List 2 : https://bit.ly/3VrUqrj
Build Projects and master the most important topics
Projects
Projects Videos —
All the projects, data structures, SQL, algorithms, system design, Data Science and ML , Data Analytics, Data Engineering, , Implemented Data Science and ML projects, Implemented Data Engineering Projects, Implemented Deep Learning Projects, Implemented Machine Learning Ops Projects, Implemented Time Series Analysis and Forecasting Projects, Implemented Applied Machine Learning Projects, Implemented Tensorflow and Keras Projects, Implemented PyTorch Projects, Implemented Scikit Learn Projects, Implemented Big Data Projects, Implemented Cloud Machine Learning Projects, Implemented Neural Networks Projects, Implemented OpenCV Projects,Complete ML Research Papers Summarized, Implemented Data Analytics projects, Implemented Data Visualization Projects, Implemented Data Mining Projects, Implemented Natural Leaning Processing Projects, MLOps and Deep Learning, Applied Machine Learning with Projects Series, PyTorch with Projects Series, Tensorflow and Keras with Projects Series, Scikit Learn Series with Projects, Time Series Analysis and Forecasting with Projects Series, ML System Design Case Studies Series videos will be published on our youtube channel ( just launched).
Thanks and Subscribe today!
Ignito Youtube Channel