


[System Design Tech Case Study Pulse #35] 7 Trillion Messages Daily : Magic Behind LinkedIn Architecture and How It Actually Works
With detailed explanation and flow chart....


Hi All,
LinkedIn's data infrastructure, centered around Apache Kafka, plays a crucial role in processing over 7 trillion messages daily. This feat allows LinkedIn to handle the massive data flow generated by its 740+ million members, powering real-time features, analytics, and data-driven decision making across the platform
Let's dive deep into how LinkedIn engineered this system, exploring the key architectural decisions, scaling strategies, and optimizations that enable efficient processing of this enormous volume of messages.
Learn how to Design Facebook Newsfeed
System Overview
Before we delve into LinkedIn's Kafka-based data pipeline architecture, let's look at some key metrics that highlight the scale of its operations:
- Active members: 740+ million
- Daily messages processed: 7 trillion+
- Kafka clusters: 100+
- Kafka brokers: 4000+
- Daily data volume: Multiple petabytes
- Message latency target: < 10ms for 99.9% of messages
- Availability: 99.99%+
- Peak throughput: Millions of messages per second
- Data retention period: Configurable, typically 7 days to several months
- Supported data types: User activities, connection events, content updates, metrics, logs
- Kafka consumers: Hundreds of microservices and data processing systems
How Real World Scalable Systems are Build — 200+ System Design Case Studies:
System Design Den : Must Know System Design Case Studies
[System Design Case Study #27] 3 Billion Daily Users : How Youtube Actually Scales
[System Design Tech Case Study Pulse #17] How Discord's Real-Time Chat Scales to 200+ Million Users
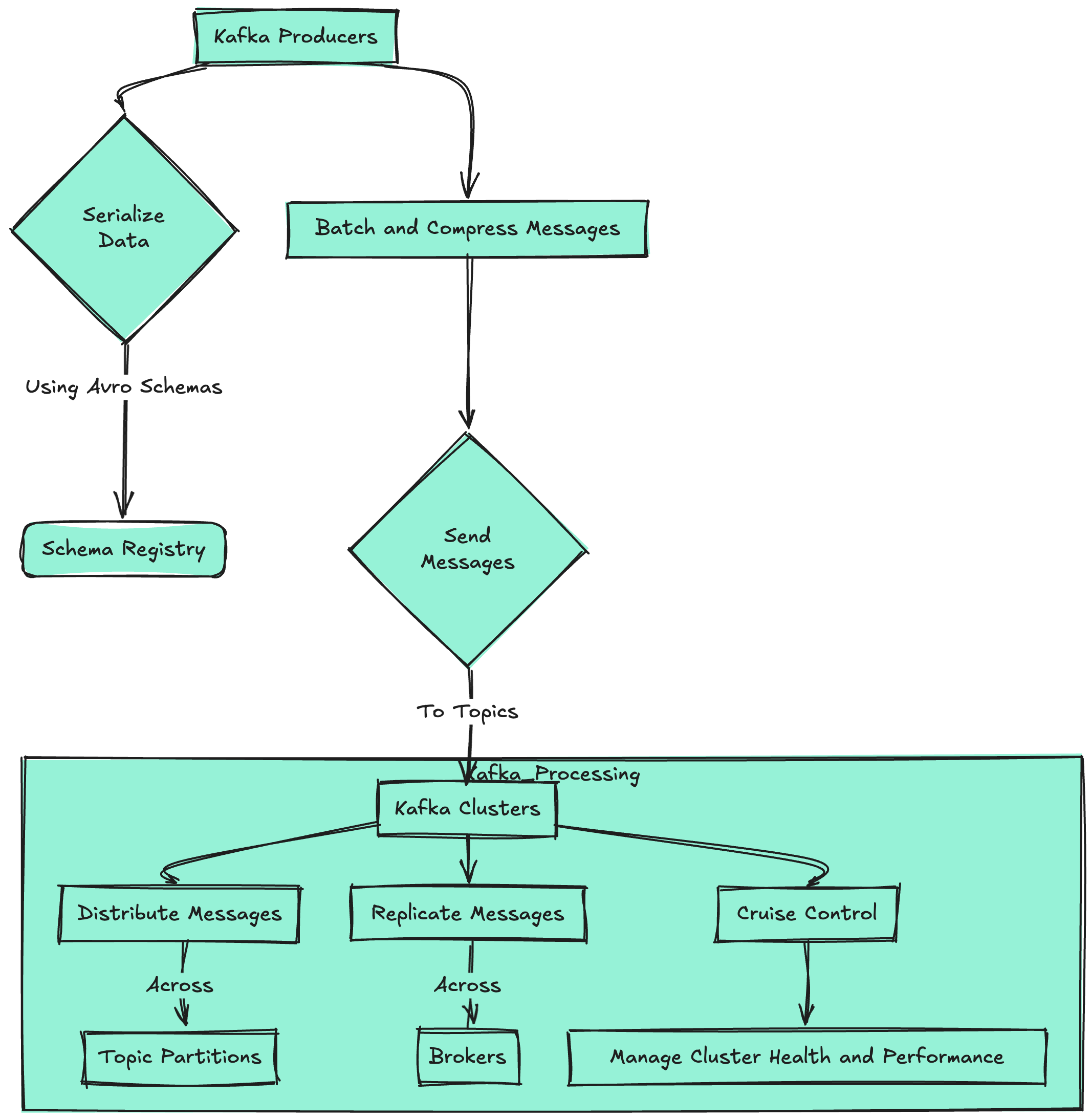
How Linkedin Acrchitecture works (Behind the Tech ) —
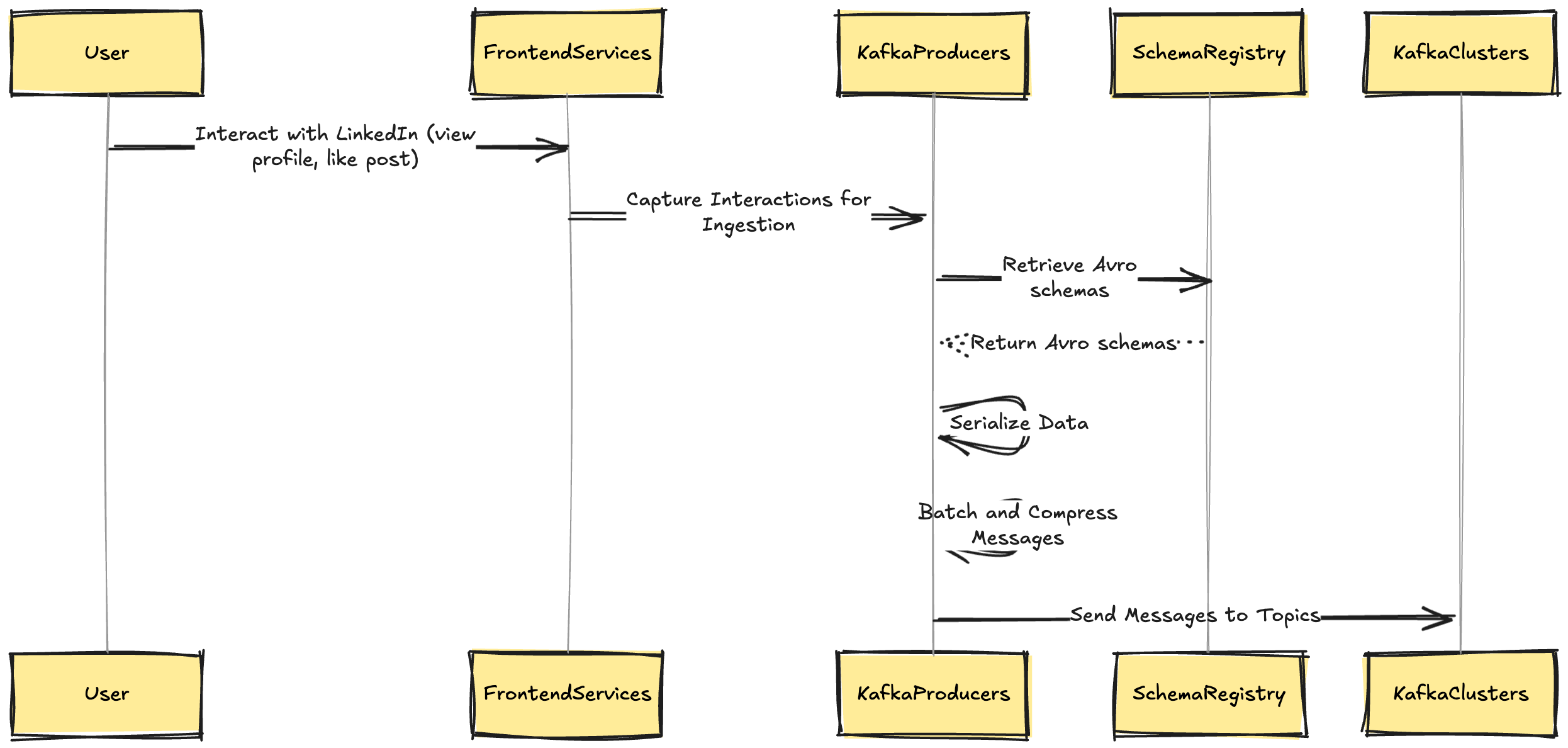
1. Data Generation:
- A user interacts with LinkedIn's platform (e.g., viewing a profile, liking a post).
- Frontend Services capture these interactions and prepare them for ingestion.
2. Data Ingestion:
- Kafka Producers serialize the data using Avro schemas from the Schema Registry.