
System Design 101 : Low level Design, High Level Design and Consistent Hashing
With Code and Case Studies...
Find complete Post here - Link
WHY you should take ONLY these courses to sky rocket your Data Science and ML Journey with Projects
Read about System Design 101 : Distributed Message Queue
Follow Github : Link
This post has been organized as —
High-Level Design:
System Architecture:
Microservices-based approach
Independent components communicating through APIs
Components:
User Interface (UI)
API Gateway
Microservices
Databases
External Services
Scalability and Performance:
Horizontal Scaling
Caching
Asynchronous Processing
Performance Monitoring
Availability and Fault Tolerance:
Redundancy
Automated Failover
Fault Isolation
Monitoring and Alerting
Data Storage and Management:
Relational Databases
NoSQL Databases
Caching
Data Replication
Backup and Recovery
Security:
Authentication and Authorization
Encryption
Input Validation and Sanitization
Security Auditing and Logging
Security Testing
Integration and APIs:
API Layer
API Documentation
Integration Patterns
Rate Limiting and Throttling
User Interface and User Experience:
User-Centered Design
Responsive Design
Intuitive Navigation
Consistency and Visual Hierarchy
Feedback and Validation
Monitoring and Logging:
Health Monitoring
Performance Monitoring
Log Management
Alerting and Notifications
Log Analysis and Reporting
Low-Level Design:
Detailed Component Design:
User Interface (UI)
API Gateway
Microservices
Databases
Algorithms and Data Structures:
Search Algorithms
Sorting Algorithms
Data Structures
Caching Algorithms
Database Schema Design
Caching and Performance Optimization
Error Handling and Exception Management:
Error Classification
Error Logging
Exception Handling
Error Messaging and Responses
Concurrency and Threading:
Thread Pooling
Synchronization Mechanisms
Asynchronous Processing
Parallel Execution
Third-Party Integrations:
API-based Integration
Adapter or Wrapper Patterns
Webhooks or Event-driven Integrations
Data Transformation and Mapping
Testing and Quality Assurance:
Unit Testing
Integration Testing
Performance Testing
Security Testing
Regression Testing
Load Testing
User Acceptance Testing (UAT)
Continuous Integration and Deployment
Code Reviews and Static Analysis
Quality Assurance
Follow - Codersmojo
Let’s get started.
High-Level Design:
System Architecture: The overall architecture of the system follows a microservices-based approach, where different components are designed as independent services that communicate with each other through APIs.
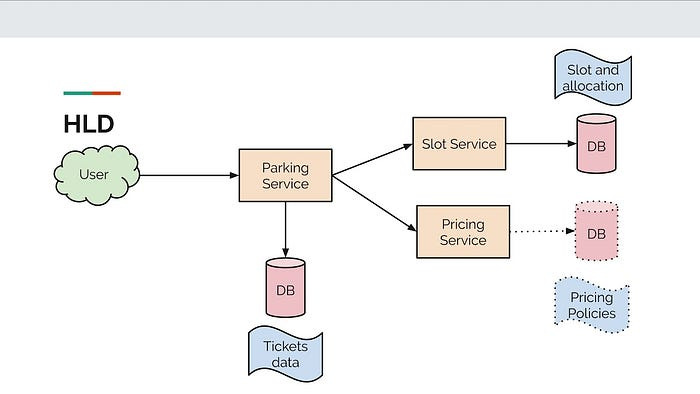
Pic credits : Medium
The system consists of the following components:
User Interface (UI): This component handles the presentation layer and provides an intuitive and user-friendly interface for users to interact with the system.
API Gateway: The API Gateway acts as a single entry point for all client requests and manages the routing of requests to the appropriate microservices. It also handles authentication, authorization, and rate limiting.
Microservices: The system is decomposed into multiple microservices, each responsible for a specific business functionality. These microservices are designed to be loosely coupled, allowing for independent development, deployment, and scalability. They communicate with each other via synchronous or asynchronous messaging.
Databases: Data storage and management are handled by different types of databases based on the requirements of each microservice. Relational databases, NoSQL databases, and caching mechanisms are used to ensure efficient data storage and retrieval.
External Services: The system integrates with various external services such as payment gateways, email providers, and third-party APIs. Integration with these services is done through well-defined APIs.
Scalability and Performance: To handle increasing loads and ensure optimal performance, the system employs several strategies:
Horizontal Scaling: The microservices architecture allows individual services to be scaled independently based on demand. Additional instances of a microservice can be deployed to handle increased traffic, and load balancers distribute the requests evenly across these instances.
Caching: Caching is utilized to reduce the load on the databases and improve response times. A distributed caching system such as Redis or Memcached is employed to cache frequently accessed data or computation results.
Asynchronous Processing: Long-running tasks or resource-intensive operations are offloaded to background workers or message queues, reducing the response time of the main API requests.
Performance Monitoring: The system incorporates monitoring tools that track key performance metrics such as response times, throughput, and resource utilization. This data is used for performance analysis, capacity planning, and identifying bottlenecks.
Availability and Fault Tolerance: The system maintains high availability and recovers from failures through the following measures:
Redundancy: Critical components, such as the API Gateway and databases, are designed with redundancy in mind. Multiple instances of these components are deployed across different servers or regions to ensure availability even if some instances fail.
Automated Failover: Load balancers and clustering techniques are employed to automatically detect failures and redirect traffic to healthy instances. This minimizes service disruptions and ensures seamless failover.
Fault Isolation: By adopting a microservices architecture, failures in one service are isolated and do not impact the entire system. This improves fault tolerance and allows for easier troubleshooting and debugging.
Monitoring and Alerting: Continuous monitoring of system health and performance helps detect anomalies and potential failures. Alerts and notifications are triggered to the operations team in case of abnormal behavior, enabling them to take corrective actions promptly.
Data Storage and Management: The system employs various strategies for storing and managing data:
Relational Databases: For structured data, a relational database such as MySQL or PostgreSQL is used. The database schema is designed to efficiently represent the relationships between entities and support complex queries.
NoSQL Databases: Unstructured or semi-structured data is stored in NoSQL databases like MongoDB or Cassandra. These databases provide flexibility and scalability for handling large volumes of data.
Caching: Frequently accessed data or computation results are cached using a distributed caching system like Redis. This reduces the load on databases and improves response times.
Data Replication: To ensure data availability and resilience, data replication techniques such as master-slave replication or sharding are employed. Data is replicated across multiple nodes or shards to provide redundancy and improve read performance.
Backup and Recovery: Regular backups of databases are performed to ensure data integrity and facilitate disaster recovery. Backup strategies include full backups, incremental backups, or continuous replication to secondary storage.
Security: The system incorporates various measures to ensure the security of the system and protect against threats:
Authentication and Authorization: User authentication is implemented using industry-standard protocols like OAuth or JWT. Role-based access control (RBAC) is used to enforce authorization policies and restrict access to sensitive resources.
Encryption: Sensitive data is encrypted both in transit and at rest. Secure communication channels, such as HTTPS, are used to protect data during transmission. Encryption algorithms and best practices are followed to safeguard stored data.
Input Validation and Sanitization: User input is validated and sanitized to prevent common security vulnerabilities like SQL injection or cross-site scripting (XSS) attacks. Input validation is performed at both the client-side and server-side.
Security Auditing and Logging: Comprehensive logging mechanisms are implemented to capture security-related events and activities. Logs are regularly reviewed, and security audits are conducted to identify any potential vulnerabilities or breaches.
Security Testing: The system undergoes regular security testing, including vulnerability assessments and penetration testing. Automated tools and manual reviews are used to identify and address security vulnerabilities.
Integration and APIs: The system integrates with external services and follows API design principles:
API Layer: The system exposes a set of well-defined APIs that allow external services, third-party applications, or client applications to interact with the system. The APIs follow RESTful or GraphQL principles, providing a clear and consistent interface.
API Documentation: Detailed documentation is provided for the APIs, including endpoints, request/response formats, authentication requirements, and error handling. This documentation helps developers understand and effectively use the system’s APIs.
Integration Patterns: Depending on the requirements, the system supports various integration patterns such as synchronous request-response, asynchronous messaging, or event-driven architectures. These patterns enable seamless communication and integration with external services.
Rate Limiting and Throttling: To manage and control the usage of APIs, rate limiting and throttling mechanisms are implemented. These mechanisms prevent abuse, protect system resources, and ensure fair access to the system.
User Interface and User Experience: The design principles and considerations for creating an intuitive and user-friendly interface are as follows:
User-Centered Design: The user interface is designed with a focus on the needs and goals of the users. User research, usability testing, and iterative design processes are employed to create an interface that meets user expectations.
Responsive Design: The user interface is designed to be responsive and adaptable to different devices and screen sizes. This ensures a consistent and optimized experience across desktop, mobile, and tablet devices.
Intuitive Navigation: Clear and logical navigation paths are implemented to help users easily navigate through different sections of the system. User-friendly menus, breadcrumbs, and search functionality are provided for efficient information retrieval.
Consistency and Visual Hierarchy: Consistent visual elements, typography, and color schemes are used to provide a cohesive user experience. Visual hierarchy is employed to highlight important information and guide users’ attention.
Feedback and Validation: Interactive elements provide feedback to users, confirming successful actions, displaying error messages, or guiding them through form validation. This helps users understand the system’s behavior and avoid mistakes.
Monitoring and Logging: The system incorporates mechanisms for monitoring the system’s health and performance and capturing logs:
Health Monitoring: Monitoring tools are used to continuously check the availability and performance of different components, including servers, databases, and microservices. Metrics such as CPU usage, memory utilization, and response times are monitored.
Performance Monitoring: Performance monitoring tools are employed to track key performance indicators (KPIs) such as response times, throughput, and resource utilization. This data helps identify performance bottlenecks and optimize system performance.
Log Management: Logs are generated by various system components and are stored centrally for analysis and troubleshooting. Logging frameworks and tools are used to capture relevant events, errors, and debugging information.
Alerting and Notifications: Thresholds and rules are set up in the monitoring system to trigger alerts and notifications when specific conditions or anomalies are detected. This enables proactive identification and resolution of issues.
Log Analysis and Reporting: Log data is analyzed using log analysis tools to gain insights into system behavior, identify patterns, and troubleshoot issues. Reports and dashboards are generated to provide visibility into system performance and health.
Low-Level Design:
Detailed Component Design: The low-level design of each individual component involves defining their responsibilities, interfaces, and interactions. It includes:
User Interface (UI): The UI component includes the design of web pages or mobile screens, their layout, visual elements, and interaction patterns. It interacts with the backend components through API calls to fetch and submit data.
API Gateway: The API Gateway component is responsible for handling incoming client requests and routing them to the appropriate microservices. It provides a unified interface for API consumers and enforces security, authentication, and rate limiting.
Microservices: Each microservice is designed with a specific business functionality and has well-defined APIs. The low-level design includes specifying the data models, business logic, and interactions with other microservices. The microservices communicate with each other through synchronous HTTP calls, asynchronous messaging systems, or event-driven architectures.
Databases: The low-level design of databases involves defining the schema, tables, relationships, and indexes. It includes specifying data access patterns, optimizing queries, and ensuring data consistency and integrity.
Algorithms and Data Structures: The system utilizes various algorithms and data structures for efficient processing and storage of data. Some examples include:
Search Algorithms: Algorithms like binary search or hash-based search are used to efficiently retrieve data from sorted or indexed data structures.
Sorting Algorithms: Sorting algorithms like quicksort or mergesort are used to order data in ascending or descending order based on specific criteria.
Data Structures: Data structures such as arrays, linked lists, trees (binary, B-trees), hash tables, or graphs are employed based on the requirements of different components.
Caching Algorithms: LRU (Least Recently Used) or LFU (Least Frequently Used) caching algorithms are used to determine which data should be cached or evicted from the cache.
Database Schema Design: The database schema design involves specifying the tables, their columns, data types, relationships (one-to-one, one-to-many, many-to-many), and constraints. It includes considerations for normalization, denormalization, indexing strategies, and query optimization. The schema design ensures efficient storage, retrieval, and manipulation of data.
Caching and Performance Optimization: Caching is utilized to improve performance, and specific strategies are employed for optimal caching:
Distributed Caching: A distributed caching system like Redis or Memcached is employed to store frequently accessed data in memory. The caching system is designed to be distributed across multiple nodes, ensuring high availability and scalability.
Cache Invalidation: Strategies such as time-based expiration, event-based invalidation, or manual invalidation are used to invalidate cached data when the underlying data changes. This ensures data consistency between the cache and the data source.
Cache Segmentation: Large datasets or frequently accessed data can be segmented into multiple caches based on access patterns. This allows for efficient management of caches and reduces cache lookup overhead.
Cache Synchronization: In distributed systems where data is replicated across multiple caches, cache synchronization mechanisms like cache coherence protocols or cache invalidation techniques are employed to ensure consistency among caches.
Error Handling and Exception Management: The system follows a comprehensive approach to handle errors and exceptions:
Error Classification: Errors are classified into different categories based on their severity and impact on the system. Common categories include client errors (e.g., invalid input), server errors (e.g., internal server failure), and third-party service errors.
Error Logging: Errors and exceptions are logged with relevant information such as timestamps, error messages, stack traces, and associated request/response data. This facilitates debugging and troubleshooting.
Exception Handling: Exception handling mechanisms, such as try-catch blocks, are implemented at appropriate levels within the system to catch and handle exceptions gracefully. Specific exception types are defined to differentiate between different types of errors.
Error Messaging and Responses: Clear and informative error messages are provided to users or clients to help them understand the nature of the error and guide them towards resolution. Error responses follow standard formats (e.g., JSON or XML) and include appropriate HTTP status codes.
Concurrency and Threading: To handle concurrent requests and manage threads effectively, the system employs the following strategies:
Thread Pooling: A thread pool is used to manage a pool of reusable threads. This allows for efficient handling of concurrent requests, as threads are not created and destroyed for every request.
Synchronization Mechanisms: Synchronization techniques such as locks, semaphores, or mutexes are used to ensure thread safety and prevent race conditions when accessing shared resources.
Asynchronous Processing: Asynchronous programming paradigms, such as callbacks, promises, or async/await, are utilized to handle concurrent requests without blocking threads. This improves overall system responsiveness and scalability.
Parallel Execution: In scenarios where parallelism is beneficial, parallel processing techniques, such as multi-threading or parallel programming models like MapReduce, are employed to divide tasks across multiple threads or processors.
Third-Party Integrations: The system incorporates third-party integrations using the following design considerations and patterns:
API-based Integration: External services or APIs are integrated into the system by defining interfaces and contracts that specify how the system interacts with them. This allows for seamless communication and data exchange between the system and external services.
Adapter or Wrapper Patterns: Adapter or wrapper patterns are used to encapsulate the specific APIs or protocols of external services and provide a unified interface within the system. This simplifies integration and decouples the system from changes in the external services.
Webhooks or Event-driven Integrations: Event-driven architectures or webhooks are employed to enable asynchronous and real-time interactions with external services. This allows the system to react to events or notifications triggered by external services.
Data Transformation and Mapping: Data transformation and mapping techniques are employed to ensure compatibility between data formats and structures used by the system and external services. This includes mapping data fields, converting data types, or applying data transformations during data exchange.
Testing and Quality Assurance: To ensure the system’s quality and reliability, comprehensive testing strategies and quality assurance practices are followed:
Unit Testing: Each component is thoroughly tested in isolation using unit tests. Mocking frameworks are used to simulate dependencies and ensure independent testing. Test coverage tools are employed to assess the completeness of unit tests.
Integration Testing: Integration tests verify the interactions and compatibility between different components or services. This includes testing API integrations, data flow between microservices, and external service integrations.
Performance Testing: Performance testing is conducted to evaluate the system’s performance under different load conditions. Tools like JMeter or Gatling are used to simulate high loads and measure response times, throughput, and resource utilization.
Security Testing: Security testing, including vulnerability assessments, penetration testing, and security code reviews, is conducted to identify and address potential security vulnerabilities. Techniques such as OWASP Top 10 testing, input validation testing, and authentication/authorization testing are employed.
Regression Testing: Regression tests are performed to ensure that system modifications or new feature additions do not introduce unintended side effects or regressions in existing functionality. Automated regression testing frameworks or tools are used to streamline this process.
Load Testing: Load testing is conducted to assess the system’s performance and stability under expected or peak loads. It involves simulating concurrent user interactions and measuring response times, throughput, and resource utilization.
User Acceptance Testing (UAT): UAT involves engaging end-users to test the system and provide feedback on its usability and functionality. This ensures that the system meets user requirements and expectations.
Continuous Integration and Deployment: Continuous integration (CI) and continuous deployment (CD) practices are followed to automate the build, testing, and deployment processes. This ensures faster feedback cycles, early detection of issues, and frequent releases with improved quality.
Code Reviews and Static Analysis: Code reviews are conducted to ensure adherence to coding standards, identify potential bugs or vulnerabilities, and share knowledge among team members. Static analysis tools are used to analyze code for potential issues, code smells, or security vulnerabilities.
Quality Assurance Processes: Quality assurance practices such as peer reviews, documentation reviews, and adherence to coding guidelines and best practices are followed to maintain high-quality code and system reliability.
Consistent Hashing:
Hashing is a technique used to map data of arbitrary size to a fixed-size value, known as a hash. It is commonly used for data indexing, data retrieval, or ensuring data integrity.
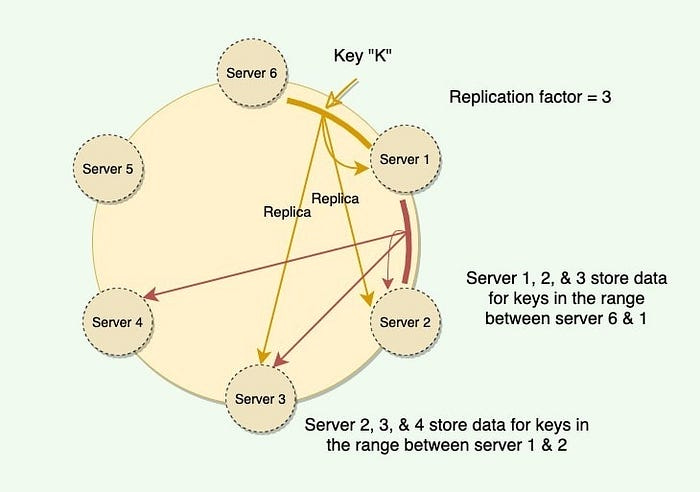
Pic credits : Medium
Problem of Data Distribution: In a distributed system, distributing data across multiple nodes can be challenging. Traditional hashing techniques, such as modulo hashing, can lead to significant data redistribution when nodes are added or removed, causing performance degradation and increased overhead.
Basic Hashing: Basic hashing techniques involve using modulo or division operations to map data to a fixed number of nodes or buckets. When nodes are added or removed, the entire data distribution needs to be recalculated, resulting in data movement and disruption.
Consistent Hashing Algorithm: Consistent hashing solves the data distribution problem by introducing a hash ring and assigning each node or bucket a position on the ring. Data is mapped to the nearest node clockwise on the ring.
When a node is added or removed, only a fraction of the data needs to be remapped, minimizing data redistribution. Each node is responsible for a range of hash values on the ring, and additional virtual nodes can be introduced to balance the data distribution.
Ring Structure and Virtual Nodes: The consistent hashing algorithm uses a ring structure, where the hash values are treated as a circular continuum. Nodes are placed on the ring based on their hash values, forming a distributed structure.
Virtual nodes are introduced to balance the data distribution among physical nodes. Each physical node can be represented by multiple virtual nodes on the ring, increasing the opportunities for data distribution.
Load Balancing and Scaling: Consistent hashing enables load balancing by distributing the data across multiple nodes uniformly. As the number of nodes increases or decreases, the data distribution remains stable, and the load is evenly distributed.
Scaling the system becomes easier with consistent hashing, as adding or removing nodes requires redistributing only a portion of the data, minimizing disruption and maintaining system performance.
Failure Handling and Resilience: Consistent hashing provides resilience in the face of node failures. When a node fails, the data originally assigned to that node is redirected to the next available node in the clockwise direction on the ring, ensuring data availability and minimizing the impact of node failures.
Use Cases and Applications: Consistent hashing finds applications in various distributed systems and scenarios, including:
Distributed Caching: Consistent hashing is commonly used in distributed caching systems like Memcached or Redis. It allows for efficient data distribution across cache nodes, ensuring high cache hit rates and minimizing cache misses.
Content Delivery Networks (CDNs): CDNs use consistent hashing to distribute content across edge servers located worldwide. It ensures that content requests are directed to the nearest server, reducing latency and improving content delivery performance.
Peer-to-Peer Networks: Consistent hashing is utilized in peer-to-peer networks to allocate data chunks or resources among participating peers. It enables efficient lookup and retrieval of data in a decentralized manner.
Key-Value Stores: Distributed key-value stores, such as DynamoDB or Riak, employ consistent hashing to partition and distribute data across multiple storage nodes. It allows for scalable storage and retrieval of key-value pairs.
Database Sharding: Sharding databases horizontally using consistent hashing enables efficient data distribution and scalability. It ensures that each shard handles a balanced load and minimizes data movement when adding or removing shards.
Load Balancers: Consistent hashing algorithms are used in load balancers to distribute incoming requests across multiple backend servers or services. It ensures that requests are consistently routed to the same server based on their hashed key, enabling session affinity and minimizing request redirection.
Distributed File Systems: Distributed file systems like Hadoop HDFS or Cassandra use consistent hashing to distribute file blocks across multiple storage nodes. It allows for parallel processing, fault tolerance, and scalable storage.
Projects Videos —
All the projects, data structures, SQL, algorithms, system design, Data Science and ML , Data Analytics, Data Engineering, , Implemented Data Science and ML projects, Implemented Data Engineering Projects, Implemented Deep Learning Projects, Implemented Machine Learning Ops Projects, Implemented Time Series Analysis and Forecasting Projects, Implemented Applied Machine Learning Projects, Implemented Tensorflow and Keras Projects, Implemented PyTorch Projects, Implemented Scikit Learn Projects, Implemented Big Data Projects, Implemented Cloud Machine Learning Projects, Implemented Neural Networks Projects, Implemented OpenCV Projects,Complete ML Research Papers Summarized, Implemented Data Analytics projects, Implemented Data Visualization Projects, Implemented Data Mining Projects, Implemented Natural Leaning Processing Projects, MLOps and Deep Learning, Applied Machine Learning with Projects Series, PyTorch with Projects Series, Tensorflow and Keras with Projects Series, Scikit Learn Series with Projects, Time Series Analysis and Forecasting with Projects Series, ML System Design Case Studies Series videos will be published on our youtube channel ( just launched).
Subscribe today!
Subscribe and Start today!!
Github : https://bit.ly/3jFzW01
Learn how to efficiently use Python Built-in Data Structures
Part 1 of this can be found here - Link
Design Facebook Newsfeed
Design Instagram
Design Tinder
Design Google Drive
Design Messenger App
Design Linkedin
Design Whatspp
Design Dropbox
Design Yelp
Design Amazon Prime Video
Design Web Crawler
Design API Rate Limiter
Design URL shortener
Design Bookmyshow
More system design case studies coming soon! Follow - Link