


[Launching LLM System Design #7] Large Language Models: The Synergy of Architecture, Attention, and Fine-Tuning: How They Actually Work - Part 7
All the technical details you need to know...
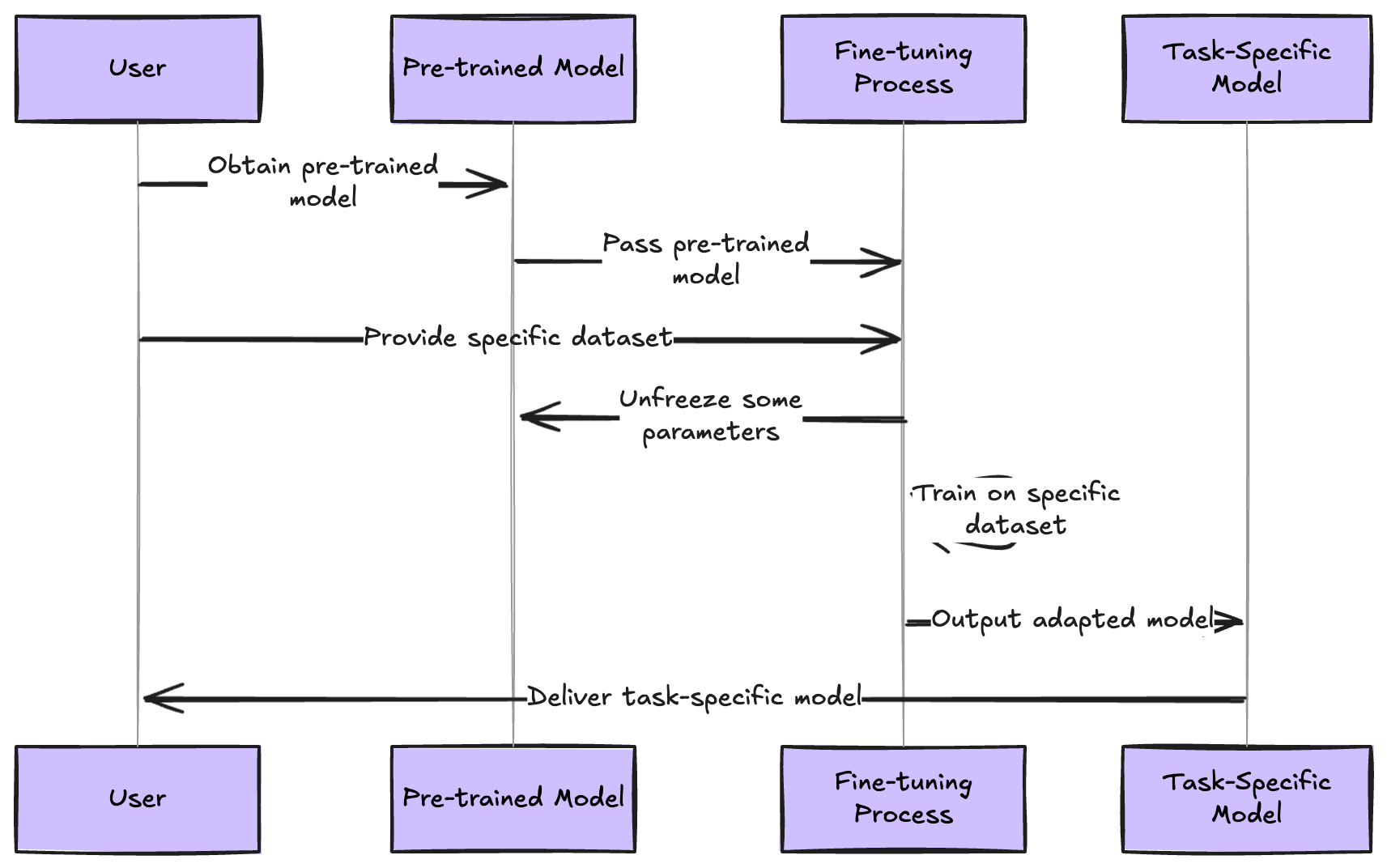
Transformer Architecture - The Foundation of Modern AI
What Are Transformers?
Think of Transformers as the revolutionary blueprint that changed everything. Before Transformers, language models processed text sequentially—like reading a book word by word, unable to skip ahead or look back efficiently. Transformers shattered this limitation by introducing parallel processing and global context awareness.
The Transformer architecture, introduced in the groundbreaking paper "Attention Is All You Need," consists of two main components:
Encoder Stack: Processes and understands input text
Decoder Stack: Generates output text based on the encoder's understanding
Diagram 1: Complete Transformer Architecture
INPUT TEXT → EMBEDDINGS → ENCODER STACK → DECODER STACK → OUTPUT
Encoder Stack: Decoder Stack:
┌─────────────────┐ ┌─────────────────┐
│ Multi-Head │ │ Masked │
│ Attention │ │ Self-Attention │
├─────────────────┤ ├─────────────────┤
│ Feed-Forward │ │ Cross-Attention│
│ Network │ ├─────────────────┤
├─────────────────┤ │ Feed-Forward │
│ Layer Norm + │ │ Network │
│ Residual │ └─────────────────┘
└─────────────────┘
↓ ×6 layers ↓ ×6 layers
Diagram 2: BERT vs GPT Architecture Comparison
BERT (Encoder-Only): GPT (Decoder-Only):
┌─────────────────┐ ┌─────────────────┐
│ INPUT │ │ INPUT │
│ "Hello [MASK] │ │ "Hello" │
│ world" │ │ │
├─────────────────┤ ├─────────────────┤
│ ENCODER STACK │ │ DECODER STACK │
│ (Bi-direct.) │ │ (Uni-direct.) │
├─────────────────┤ ├─────────────────┤
│ PREDICTION │ │ GENERATION │
│ "beautiful" │ │ "world, how" │
└─────────────────┘ └─────────────────┘
Diagram 3: Information Flow in Transformers
Text Input: "The cat sat on the mat"
Tokenization: [The] [cat] [sat] [on] [the] [mat]
↓ ↓ ↓ ↓ ↓ ↓
Embeddings: E₁ E₂ E₃ E₄ E₅ E₆
↓ ↓ ↓ ↓ ↓ ↓
Position Encoding: P₁ + P₂ + P₃ + P₄ + P₅ + P₆
↓ ↓ ↓ ↓ ↓ ↓
Multi-Head ╔═════════════════════════════╗
Attention: ║ Global Context Layer ║
╚═════════════════════════════╝
↓
Feed-Forward: Processing
↓
Output: Rich Representations
Below are the top 10 System Design Case studies for this week
Billions of Queries Daily : How Google Search Actually Works
100+ Million Requests per Second : How Amazon Shopping Cart Actually Works
Serving 132+ Million Users : Scaling for Global Transit Real Time Ride Sharing Market at Uber
3 Billion Daily Users : How Youtube Actually Scales
$100000 per BTC : How Bitcoin Actually Works
$320 Billion Crypto Transactions Volume: How Coinbase Actually Works
100K Events per Second : How Uber Real-Time Surge Pricing Actually Works
Processing 2 Billion Daily Queries : How Facebook Graph Search Actually Works
7 Trillion Messages Daily : Magic Behind LinkedIn Architecture and How It Actually Works
1 Billion Tweets Daily : Magic Behind Twitter Scaling and How It Actually Works
12 Million Daily Users: Inside Slack's Real-Time Messaging Magic and How it Actually Works
3 Billion Daily Users : How Youtube Actually Scales
1.5 Billion Swipes per Day : How Tinder Matching Actually Works
500+ Million Users Daily : How Instagram Stories Actually Work
2.9 Billion Daily Active Users : How Facebook News Feed Algorithm Actually Works
20 Billion Messages Daily: How Facebook Messenger Actually Works
8+ Billion Daily Views: How Facebook's Live Video Ranking Algorithm Works
How Discord's Real-Time Chat Scales to 200+ Million Users
80 Million Photos Daily : How Instagram Achieves Real Time Photo Sharing
Serving 1 Trillion Edges in Social Graph with 1ms Read Times : How Facebook TAO works
How Lyft Handles 2x Traffic Spikes during Peak Hours with Auto scaling Infrastructure..
Diagram 4: Encoder-Decoder Detailed Architecture
INPUT: "Translate: Hello world"
ENCODER SIDE: DECODER SIDE:
┌─────────────────┐ ┌─────────────────┐
│ INPUT │ │ OUTPUT │
│ EMBEDDING │ │ EMBEDDING │
│ + │ │ + │
│ POSITIONAL │ │ POSITIONAL │
└─────────────────┘ └─────────────────┘
↓ ↓
┌─────────────────┐ ┌─────────────────┐
│ Multi-Head │────────────→│ Cross-Attention│
│ Self-Attention │ Keys & │ (Enc-Dec Attn) │
│ │ Values │ │
└─────────────────┘ └─────────────────┘
↓ ↓
┌─────────────────┐ ┌─────────────────┐
│ Add & Norm │ │ Add & Norm │
└─────────────────┘ └─────────────────┘
↓ ↓
┌─────────────────┐ ┌─────────────────┐
│ Feed Forward │ │ Masked Multi- │
│ Network │ │ Head Attention │
└─────────────────┘ └─────────────────┘
↓ ↓
┌─────────────────┐ ┌─────────────────┐
│ Add & Norm │ │ Add & Norm │
└─────────────────┘ └─────────────────┘
↓ ↓
Context Vector ┌─────────────────┐
│ Feed Forward │
│ Network │
└─────────────────┘
↓
┌─────────────────┐
│ Add & Norm │
└─────────────────┘
↓
┌─────────────────┐
│ Linear & Softmax│
└─────────────────┘
↓
OUTPUT: "Hola mundo"
Diagram 5: How Positional Encoding Works
Position Encoding Formula: PE(pos,2i) = sin(pos/10000^(2i/d_model))
PE(pos,2i+1) = cos(pos/10000^(2i/d_model))
Position 0: [0.0, 1.0, 0.0, 1.0, 0.0, 1.0, ...]
Position 1: [0.8, 0.5, 0.1, 0.9, 0.01, 0.99, ...]
Position 2: [0.9, -0.4, 0.2, 0.8, 0.02, 0.98, ...]
Word Embeddings + Positional Encodings:
┌─────────────────────────────────────┐
│ "The": [0.1, 0.3, -0.2, 0.8, ...] │ + Position 0
│ "cat": [0.5, -0.1, 0.7, 0.2, ...] │ + Position 1
│ "sat": [0.3, 0.6, -0.4, 0.1, ...] │ + Position 2
└─────────────────────────────────────┘
↓
Final Input Representations with Position Info