
How to Efficiently Build Scalable Machine Learning Pipelines - Explained in Simple terms with Implementation Details
With code, techniques and best tips...
Hi All,
Building scalable machine learning pipelines is crucial for efficiently deploying and maintaining machine learning models in production. In this post we will cover how to build scalable machine learning pipeline in detail with code implementation ( as follows) .
WHY you should take ONLY these courses to sky rocket your Data Science and ML Journey
Read about System Design 101 : Distributed Message Queue
Mega Launch - Youtube Channel and Highly Recommended Courses to become Brilliant Data Scientist/ ML Engineer
In this post we will cover —
Data Preparation and Preprocessing:
Clean and preprocess data to handle missing values, outliers, and inconsistencies.
Normalize, standardize, or transform features as necessary.
Consider techniques like one-hot encoding, label encoding, and embedding for categorical variables.
Implement data validation and sanity checks to ensure data quality.
Feature Engineering:
Create relevant features that capture important information from the data.
Use domain knowledge to engineer features that enhance model performance.
Experiment with different feature transformation techniques.
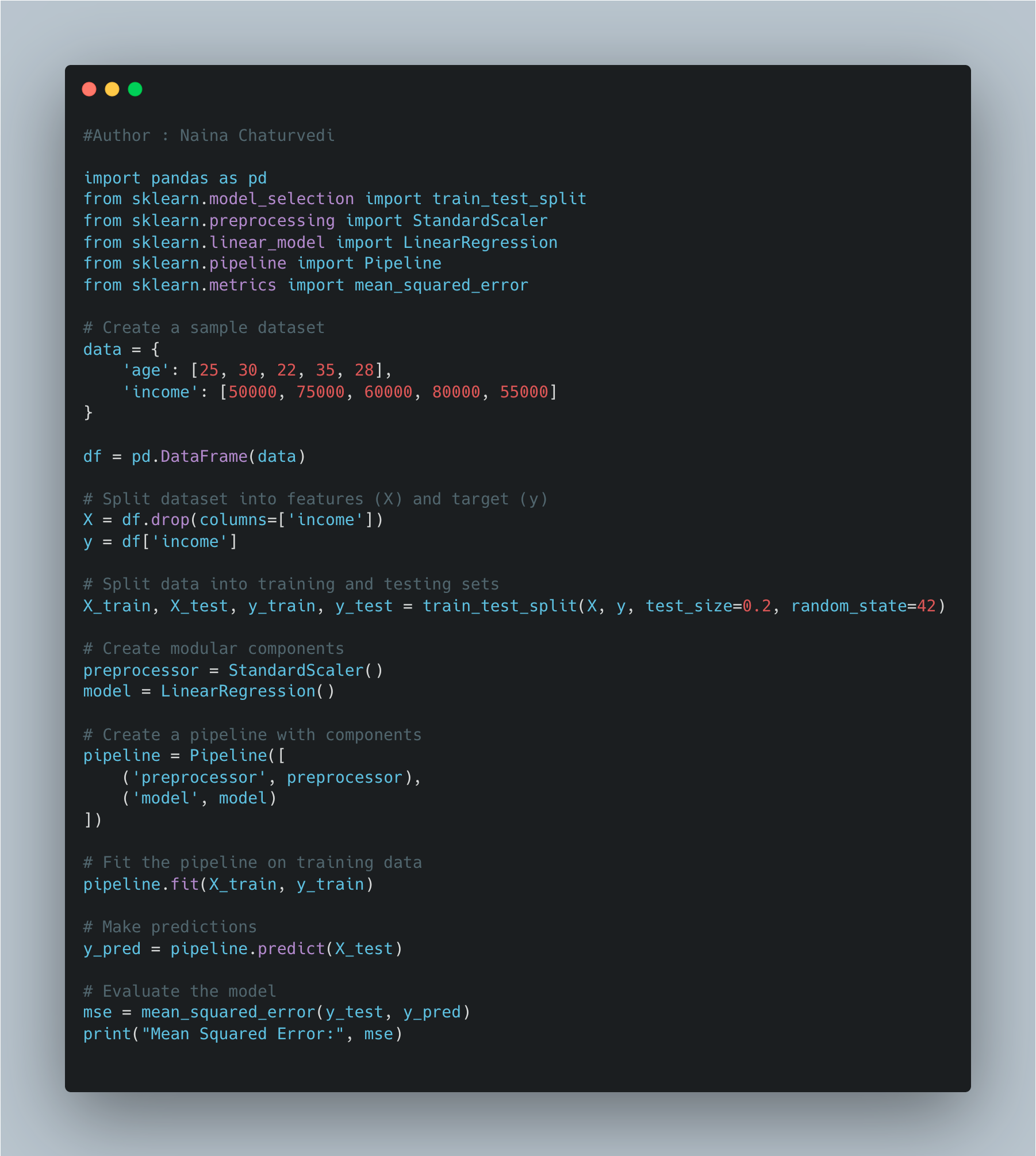
Modular Pipeline Design:
Divide the pipeline into modular components for data preprocessing, feature engineering, model training, and model evaluation.
Utilize tools like scikit-learn's
Pipelineclass to organize and automate these components.
Distributed Computing and Parallelism:
Leverage distributed computing frameworks like Apache Spark for processing large datasets in parallel.
Utilize multi-threading or multi-processing for parallel execution of tasks within a pipeline.
Model Selection and Hyperparameter Tuning:
Experiment with different algorithms and models to find the best fit for the problem.
Perform hyperparameter tuning using techniques like grid search, random search, or Bayesian optimization.
Consider ensemble methods to combine the strengths of multiple models.
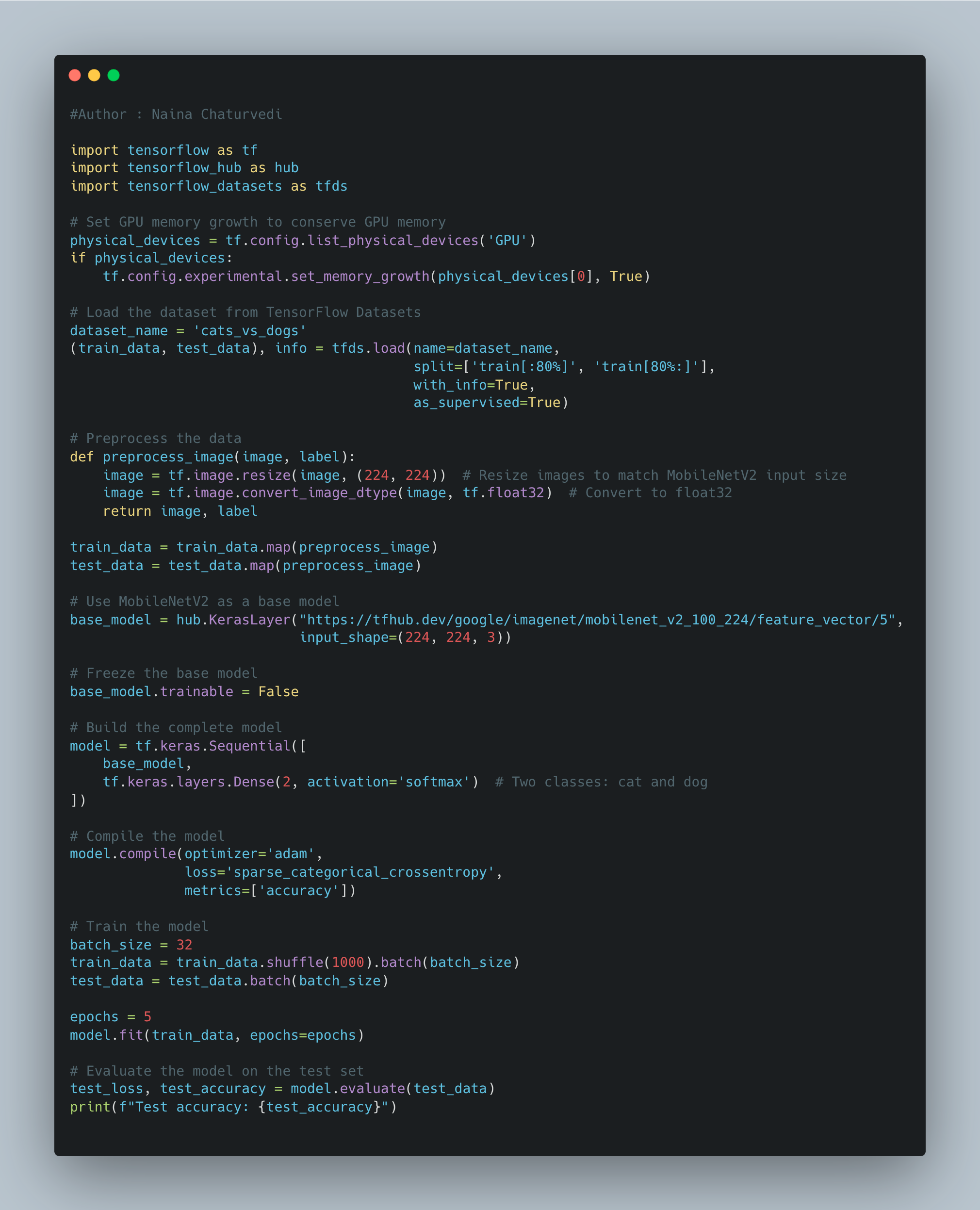
Scalable Model Training:
Use frameworks like TensorFlow or PyTorch to take advantage of GPU and distributed training capabilities.
Consider transfer learning to leverage pre-trained models and save training time.
Model Deployment and Serving:
Containerize models using tools like Docker for consistent deployment across different environments.
Utilize orchestration tools like Kubernetes to manage and scale deployments.
Design RESTful APIs or use platforms like FastAPI for serving predictions.
Monitoring and Logging:
Implement robust logging to track pipeline execution and detect errors.
Monitor model performance using metrics like accuracy, precision, recall, and F1-score.
Set up alerts for anomalies and degradation in performance.
Automated Testing and Continuous Integration:
Implement unit tests for individual pipeline components to ensure their correctness.
Set up continuous integration pipelines to automate testing and deployment processes.
Data Versioning and Reproducibility:
Use version control systems like Git for tracking changes to code and data.
Implement data versioning tools to ensure reproducibility of experiments and results.
Let’s get started —
What is Machine Learning Pipelines and why to use it?
Imagine you have a magical cookie-making factory. You start by mixing the ingredients like flour, sugar, and chocolate chips to make cookie dough. Then, you put the dough in a machine that shapes it into cookies and bakes them.
Now, let's say you want to make lots and lots of cookies really quickly. Instead of making just one cookie at a time, you might want to make many cookies all at once. That's where a "scalable cookie-making pipeline" comes in.
In the cookie-making pipeline, you have different stages or steps. First, you mix the ingredients to make the dough (that's like the first step in making cookies). Then, you have a machine that shapes the dough into cookies (just like the second step in making cookies). After that, you put all the cookies in an oven to bake them (similar to the baking step).
If you want to make even more cookies, you can add more machines to shape the dough and more ovens to bake the cookies all at the same time. This way, you can make a whole bunch of cookies really fast!
So, a scalable cookie-making pipeline is like having a special way to make a whole bunch of cookies quickly by adding more machines and ovens to make sure you can keep up with the demand for cookies. Similarly, in a scalable ML (Machine Learning) pipeline, you have steps that help you teach computers to learn things, and you can make it work faster by adding more machines to help with each step.
ML (Machine Learning) pipeline is a structured and organized sequence of data processing and model building steps that together enable the development, training, evaluation, and deployment of machine learning models. It's a framework that streamlines the end-to-end process of creating and operationalizing machine learning systems.
When to Use an ML Pipeline: ML pipelines are used whenever there is a need to create, iterate on, and deploy machine learning models in a systematic and efficient manner. They are particularly beneficial in scenarios involving:
Reproducibility: ML pipelines ensure that the same sequence of steps can be easily replicated, allowing others to reproduce the model development process reliably.
Automation: They automate repetitive tasks like data preprocessing, feature extraction, model training, and evaluation, freeing up data scientists and engineers to focus on higher-level tasks.
Modularity: Pipelines break down the process into modular components, making it easier to test and modify individual parts of the process without disrupting the entire workflow.
Experimentation: For model experimentation, pipelines enable systematic testing of various combinations of data preprocessing techniques, feature selection, hyperparameters, and algorithms.
Scalability: In situations where large datasets or complex processing are involved, pipelines facilitate parallelization and distributed computing, speeding up the overall process.
Collaboration: ML pipelines provide a common structure and language for cross-functional teams, fostering collaboration between data engineers, data scientists, and machine learning engineers.
Components of an ML Pipeline: An ML pipeline typically consists of the following components:
Data Ingestion and Preprocessing: This step involves collecting and preparing the raw data for analysis, including tasks like cleaning, transforming, and encoding data. It ensures that the data is in a suitable format for training and evaluation.
Feature Engineering: In this step, relevant features (input variables) are selected, created, or transformed from the raw data. Feature engineering plays a crucial role in improving the performance of machine learning models.
Model Selection and Training: Based on the problem and the available data, suitable machine learning algorithms and models are chosen. These models are trained on the prepared data using training algorithms.
Hyperparameter Tuning: Models often have settings called hyperparameters that control their behavior. Tuning these hyperparameters helps optimize the model's performance on unseen data.
Model Evaluation: The trained models are evaluated using separate validation or test datasets to measure their performance and generalization ability. This step helps in selecting the best-performing model.
Model Deployment: The chosen model is deployed to a production environment where it can be used to make predictions on new, unseen data.
Benefits of Using an ML Pipeline:
Efficiency: By breaking down the process into manageable steps, pipelines help automate and streamline repetitive tasks, making the development process more efficient.
Reproducibility: ML pipelines ensure that the entire process, from data preprocessing to model deployment, can be reproduced reliably, enhancing transparency and accountability.
Flexibility: Pipelines allow easy experimentation with different data processing techniques, models, and hyperparameters without disrupting the overall workflow.
Collaboration: Cross-functional teams can collaborate more effectively by following a common pipeline structure, enabling smoother communication and sharing of insights.
Scalability: Pipelines can be adapted to handle large datasets and distributed computing environments, ensuring that the process can scale as needed.
How to build Scalable ML Pipelines -
Data Preparation and Preprocessing: Clean and preprocess data to handle missing values, outliers, and inconsistencies. Normalize, standardize, or transform features as necessary. Use techniques like one-hot encoding, label encoding, embedding for categorical variables.

Feature Engineering: Create relevant features that capture important information from the data. Use domain knowledge to engineer features that enhance model performance. Experiment with different feature transformation techniques.

Modular Pipeline Design: Divide the pipeline into modular components for data preprocessing, feature engineering, model training, and model evaluation.
Distributed Computing and Parallelism: Leverage distributed computing frameworks like Apache Spark for processing large datasets in parallel. Utilize multi-threading or multi-processing for parallel execution of tasks within a pipeline.

Model Selection and Hyperparameter Tuning: Experiment with different algorithms and models to find best fit for problem. Perform hyperparameter tuning using techniques like grid search or Bayesian optimization. Use ensemble methods to combine strengths of multiple models

Scalable Model Training: Use frameworks like TensorFlow or PyTorch to take advantage of GPU and distributed training capabilities. Consider transfer learning to leverage pre-trained models and save training time.
Read complete post —
How to build Scalable ML Pipelines
53 Implemented Projects
Complete Data Scientist:
Link to the course : https://bit.ly/3wiIo8u
Run data pipelines efficiently to extract, transform, and load data.
Design and conduct experiments to uncover valuable insights and drive data-based decision making.
Build powerful recommendation systems that personalize user experiences and increase engagement.
Deploy solutions to the cloud, enabling scalable and accessible data applications.
Master the essential skills needed to excel in the field of data science.
Complete Data Engineering:
Link to the course : https://bit.ly/3A9oVs5
Learn the art of designing effective data models that ensure data integrity and efficient storage.
Construct data warehouses and data lakes to enable centralized and organized data storage.
Automate data pipelines to streamline data processing and ensure timely and accurate data availability.
Gain expertise in handling and working with massive datasets efficiently.
Become a proficient data engineer equipped with in-demand skills for building robust data infrastructures.
Complete Machine Learning Engineer:
Link to the course : https://bit.ly/3Tir8ub
Acquire advanced machine learning techniques and algorithms to solve complex problems.
Develop skills in packaging and deploying machine learning models to production environments.
Master the art of model evaluation and selection to ensure optimal performance.
Learn to implement cutting-edge algorithms and architectures for superior machine learning results.
Equip yourself with the skills required to excel as a machine learning engineer.
Complete Natural Language Processing:
Link to the course : https://bit.ly/3T7J8qY
Build models that analyze and interpret human language, enabling sentiment analysis and machine translation.
Gain hands-on experience working with real data, developing practical NLP applications.
Uncover hidden patterns and extract valuable insights from textual data.
Understand the complexities of language and apply NLP techniques to solve challenging problems.
Unlock the power of language through the application of natural language processing.
Complete Deep Learning:
Link to the course : https://bit.ly/3T5ppIo
Master the implementation of Neural Networks using the powerful PyTorch framework.
Dive deep into the world of deep learning and understand its applications in various domains.
Gain hands-on experience in developing solutions for image recognition, natural language understanding, and more.
Learn about different architectures and techniques for building robust deep learning models.
Become proficient in utilizing deep learning to tackle complex problems and drive innovation.
Complete Data Product Manager:
Link to the course : https://bit.ly/3QGUtwi
Leverage the power of data to build products that deliver personalized and impactful experiences.
Lead the development of data-driven products that position businesses ahead of the competition.
Gain a deep understanding of user behavior and preferences through data analysis.
Develop strategies to optimize product performance and drive business growth.
Become a data product manager who can harness data's potential to create successful products.
Part 1 of this can be found here - Link
Github for System Design Interviews with Case Studies
105+ System Design Case Studies
More system design case studies coming soon! Follow - Link
Things you must know in System Design -
System design basics : https://bit.ly/3SuUR0Y
Horizontal and vertical scaling : https://bit.ly/3slq5xh
Load balancing and Message queues: https://bit.ly/3sp0FP4
High level design and low level design, Consistent Hashing, Monolithic and Microservices architecture : https://bit.ly/3DnEfEm
Caching, Indexing, Proxies : https://bit.ly/3SvyVDc
Networking, How Browsers work, Content Network Delivery ( CDN) : https://bit.ly/3TOHQRb
Database Sharding, CAP Theorem, Database schema Design : https://bit.ly/3CZtfLN
Concurrency, API, Components + OOP + Abstraction : https://bit.ly/3sqQrhj
Estimation and Planning, Performance : https://bit.ly/3z9dSPN
Map Reduce, Patterns and Microservices : https://bit.ly/3zcsfmv
SQL vs NoSQL and Cloud : https://bit.ly/3z8Aa49
Let us know what do you think…
Happy learning!
-Team Ignito.